I was looking at the output of Power Query’s Query Diagnostics feature recently (again) and trying to understand it better. One of the more confusing aspects of it is the way that the Power Query engine may evaluate a query more than once during a single refresh. This is documented in the note halfway down this page, which says:
Power Query might perform evaluations that you may not have directly triggered. Some of these evaluations are performed in order to retrieve metadata so we can best optimize our queries or to provide a better user experience (such as retrieving the list of distinct values within a column that are displayed in the Filter Rows experience). Others might be related to how a connector handles parallel evaluations.
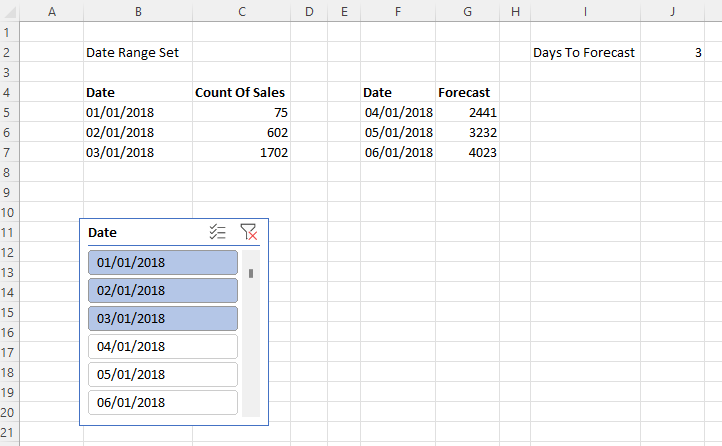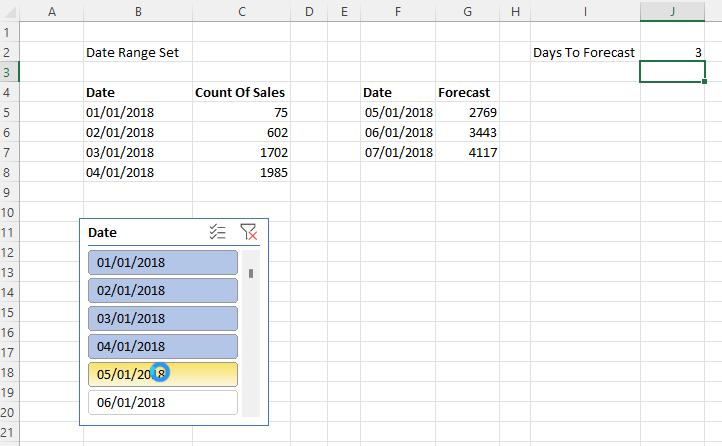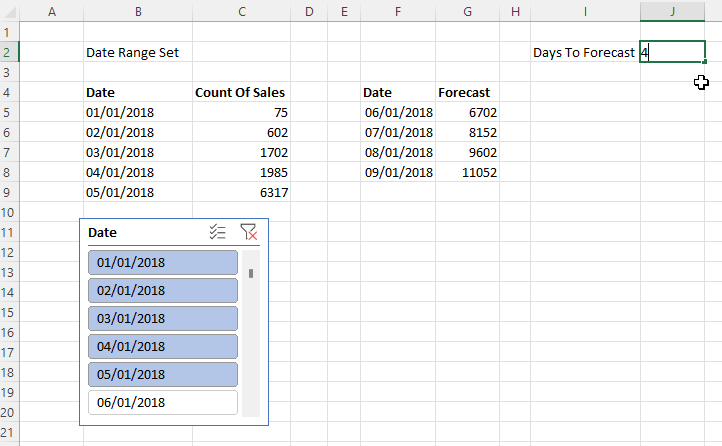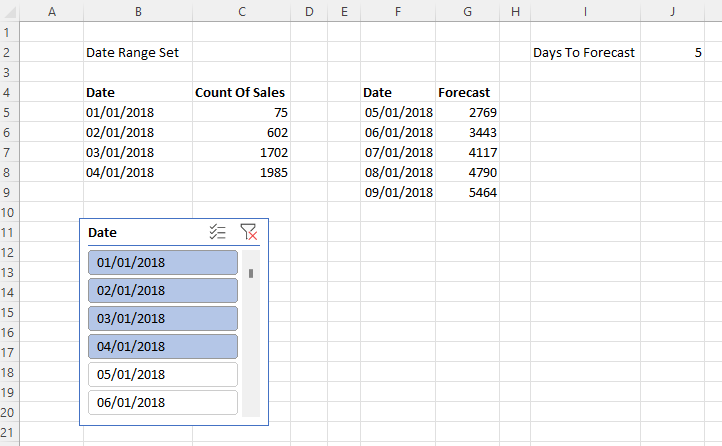
I came up with the following M query to illustrate this:
#table(
type table
[#"Activity ID"=text],
{{Diagnostics.ActivityId()}}
)
If you paste this code into a new blank query:

…you have a query that returns a table containing a single cell containing the text value returned by the Diagnostics.ActivityId M function, which I blogged about here. The output – copied from the Data pane of the main Power BI window – looks like this:

The Diagnostics.ActivityId function is interesting because it returns an identifier for the currently-running query evaluation, so in the table above the value in the Activity ID column is the identifier for the query that returned that table.
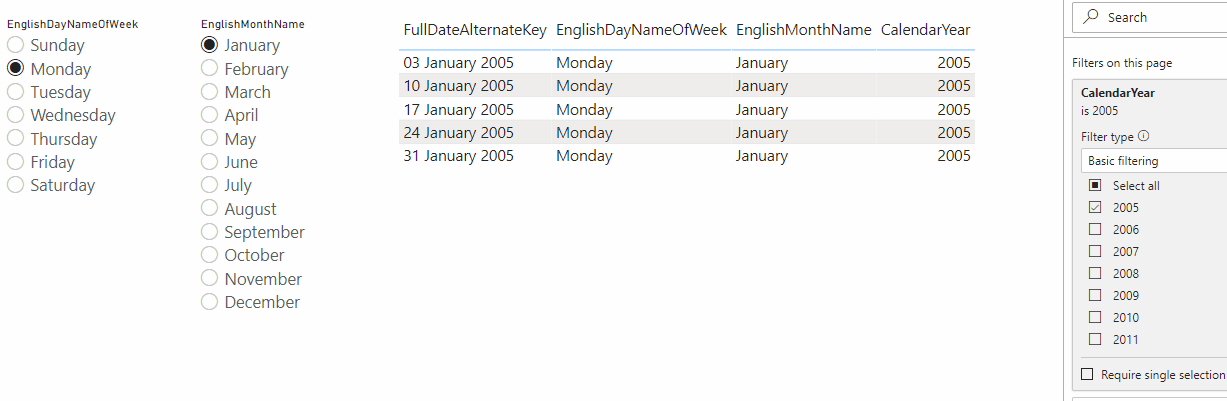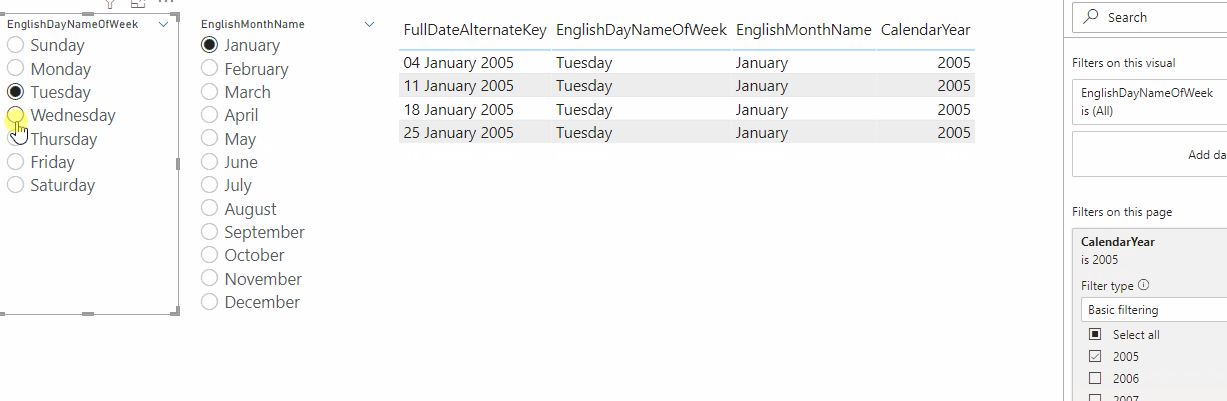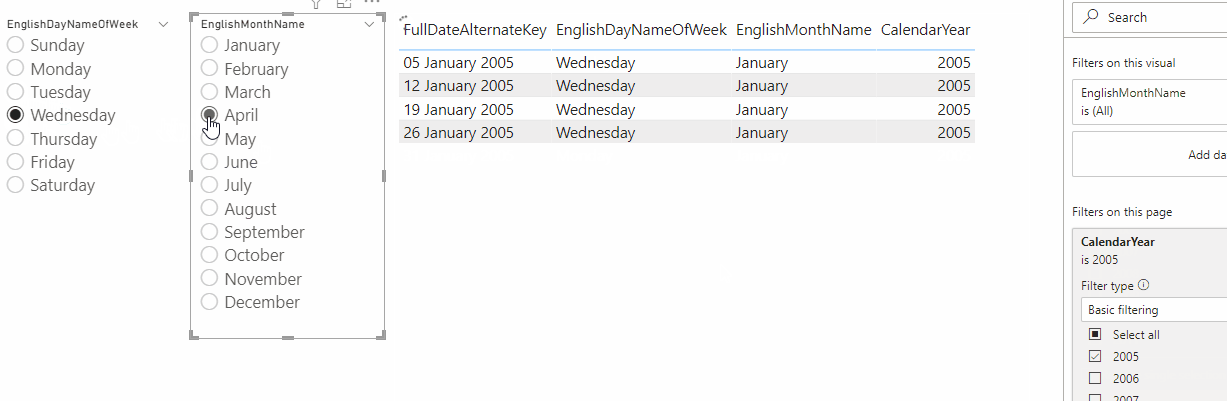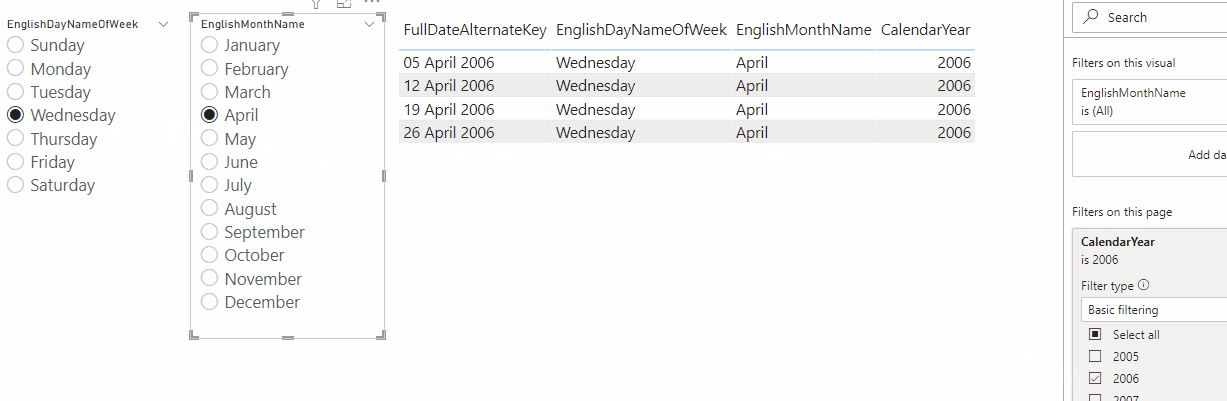
If you run a Query Diagnostics trace when refreshing this query, you’ll see that the Activity Id column of the Diagnostics_Detailed trace query contains evaluation identifier values:

The following query takes the output of a Diagnostics_Detailed trace query and gets just the unique values from the Id and Activity Id columns:
let
Source = #"Diagnostics_Detailed_2022-04-24_19:40",
#"Removed Other Columns" = Table.SelectColumns(Source,{"Id", "Activity Id"}),
#"Removed Duplicates" = Table.Distinct(#"Removed Other Columns")
in
#"Removed Duplicates"

This makes it easy to see that my query was actually evaluated (or at least partially evaluated) three times when I clicked refresh. Since the value in the Activity Id column for Id 4.10 matches the value in the table loaded into my dataset, I know that that was the evaluation that loaded my table into the dataset.