After years of meaning to learn how to use Excel Solver, this week I’ve finally made a start: I want to use it to work out the optimal way of distributing workspaces across capacities in a Fabric tenant from the point of view of CU usage. I’m a long way from knowing how to do this properly (I’ll blog about it when I’m ready) but one of the first things I found is that while there are lots of resources on the internet showing how to use Solver, there are no examples of how to use Solver when your source data is stored in the Excel Data Model, aka Power Pivot. Getting that data onto the worksheet is fairly straightforward, but what if you also need Solver to change how that data is sliced and diced? It turns out that not hard to do if you know how to use cube functions.
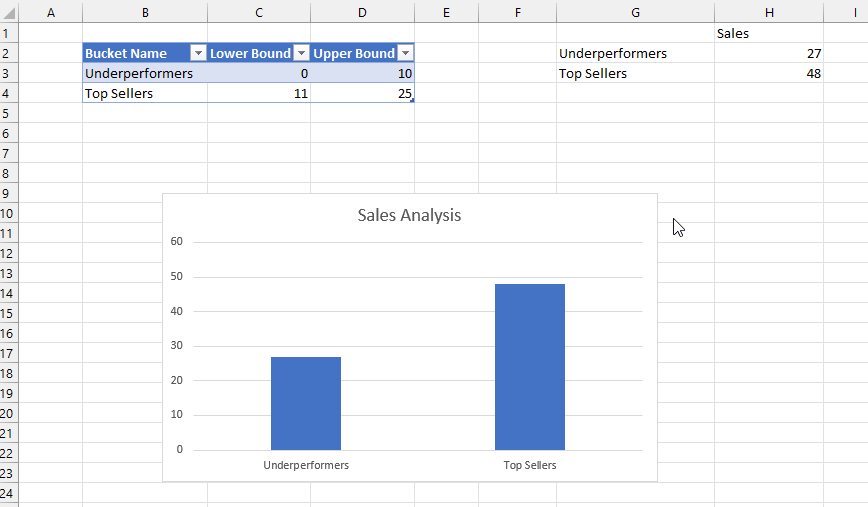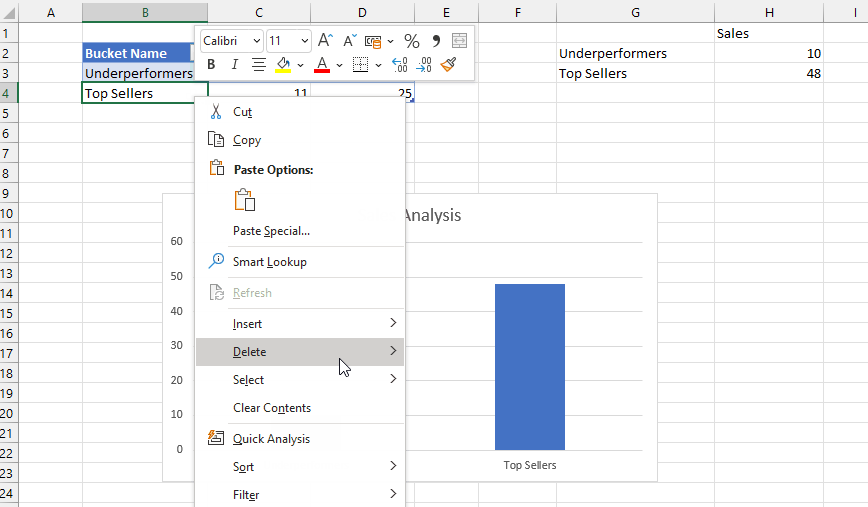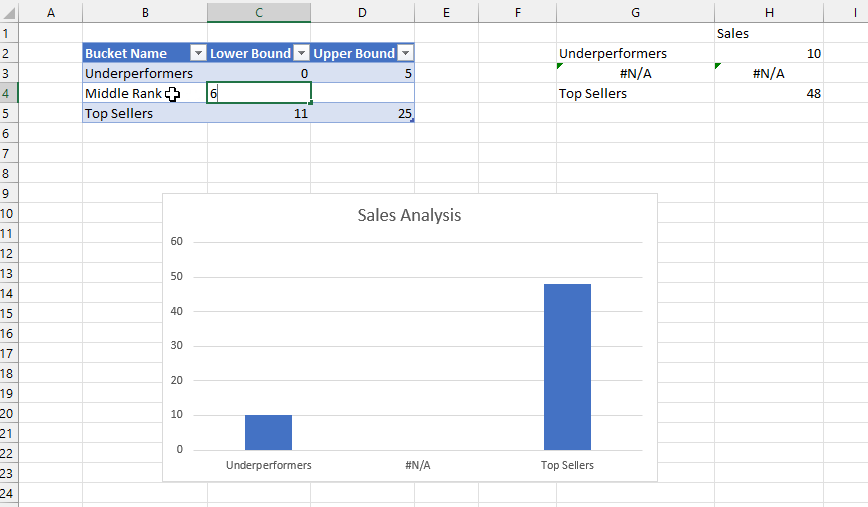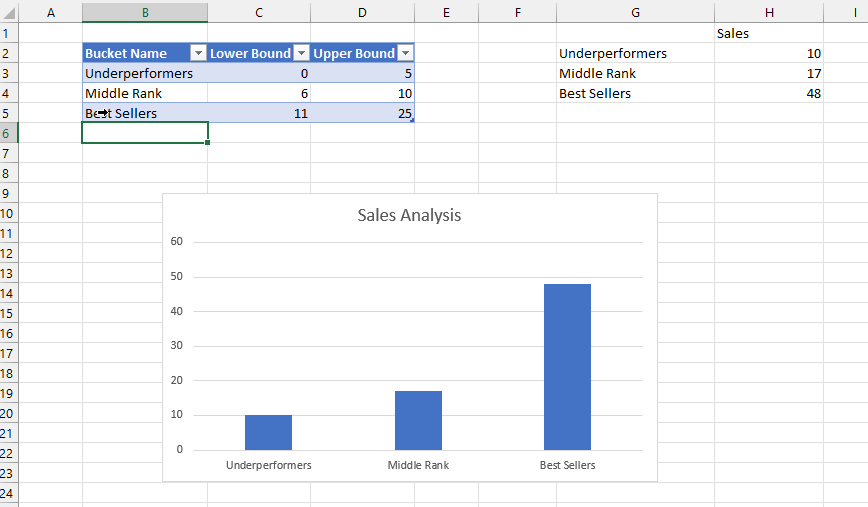
To work out how to do this, I loaded the following table into the Excel Data Model:

I then created a simple measure called Total Profit that sums the values in the Profit column:
Total Profit:=SUM(Sales[Profit])I then created a worksheet that looked like this:

Here are the cell formulas:

…and here’s a brief explanation of what’s happening here:
- Cell C2 contains the name of the connection that all the cube functions use, which is always “ThisWorkbookDataModel”
- The range B5:B7 contains CubeSet functions that return the sets of all countries, products and years. For example the formula in B5 is
CUBESET($C$2, “[Sales].[Country].[Country].MEMBERS”, “Set of Countries”) - The range C5:C7 contains CubeSetCount functions that return the number of members in the sets in the range B5:B7. For example the formula in C5 is
CUBESETCOUNT(B5) - The range C10:C12 contains integers that represent the ordinal of one of the members in each set. For example there are three members in the set of all countries, France, Germany and UK, and the integer 3 represents the third item in that set, ie the UK.
- The range D10:D12 contains CubeRankedMember functions that take these ordinals and returns the members in each set at the given ordinal. For example the formula in D10 is
CUBERANKEDMEMBER($C$2, B5, C10) - Cell C14 contains a single CubeValue function that returns the value for the Total Profit measure for the country, product and year returned in D10:D12. It is
IFERROR(CUBEVALUE($C$2, “[Measures].[Total Profit]”, $D$10, $D$11, $D$12),””)
The problem to solve is this: what combination of country, product and year returns the maximum value for Total Profit? This is a pretty stupid problem to use Solver for: you can see from the source data that obviously it’s Germany, Pears and 2024, and even if you couldn’t see it from looking at the data you could write some DAX to do this quite easily. The formulas and techniques shown here, though, will be applicable to other real-life scenarios.
Here’s how I configured Solver:

- The objective is to maximise the value in cell C14, the cell containing the value of the Total Profit measure for the selected country, product and year.
- The values to change are the values in C10:C12, the cells that contain the ordinals of the selected country, product and year. There are three types of constraints on the allowed inputs in these cells
- These cells must contain integers
- The minimum allowed value is 1
- The maximum allowed value is the value in the related cell in C5:C7 which tells you the number of items in the set of countries, products and years
- The solving method is Evolutionary
After clicking Solve and waiting a bit, I got the right answer back, 18:

One more time before someone leaves a comment: the point of this post is not to show how to use Solver to solve a realistic problem, the point is to show how you can use Solver to change integer values in cells which in turn change how values from the Excel Data Model/Power Pivot are sliced when using Excel cube functions.
Also, if you’re using cube functions with Solver in this way, you’re probably going to need to use cube functions with dynamic arrays in the way I showed in this series to make them more PivotTable-like; once you’ve got the data onto the worksheet you’ll be able to use Solver in the normal way.
Finally – if this works for Power Pivot, wouldn’t it also work with cube functions connected to a published Power BI semantic model, Azure Analysis Services or on-prem Analysis Services? Technically yes, but I would be very worried about the number of MDX queries generated when Solver runs. If you’re using Power Pivot the worst thing that could happen is that you overload your PC; if you send too many queries to Power BI, AAS or SSAS you could cause problems for other users.