Azure Data Explorer has a data type called dynamic which can be used to hold scalar values as well as arrays and property bags; you can read about it in the docs here. For example (following on from my recent series on DirectQuery on Log Analytics, starting here) the ApplicationContext column in the PowerBIDatasetsWorkspace table that holds the IDs of the dataset, report and visual that generated a DAX query (see this post for more background) is of type dynamic:

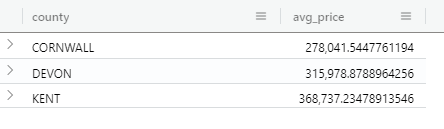
This is what the contents of the column look like:

Now you can easily extract the individual property values from this column in KQL, and indeed I did so in the KQL queries in this post, but the interesting thing is you can also extract these values in Power Query M very easily and – crucially – maintain query folding using the Record.FieldOrDefault M function in a custom column without needing to write any KQL yourself, in both Import mode and DirectQuery mode.
In order to do this, first of all you have to enter a table name or KQL query in the third parameter of AzureDataExplorer.Contents function. When you do this you can treat a dynamic column as a record even if the Power Query UI doesn’t display it as such. Here’s an example M query that shows all of this in action on the PowerBIDatasetsWorkspace table that contains Power BI data in Log Analytics:
let
Source = AzureDataExplorer.Contents(
"InsertClusterName",
"InsertDBName",
"PowerBIDatasetsWorkspace",
[
MaxRows = null,
MaxSize = null,
NoTruncate = null,
AdditionalSetStatements = null
]
),
#"Added Custom" = Table.AddColumn(
Source,
"Custom",
each Record.FieldOrDefault(
[ApplicationContext],
"DatasetId"
)
)
in
#"Added Custom"
From this query, here’s what the Custom Column dialog for the #”Added Custom” step looks like:

Here’s the output in the Power Query Editor:

And here’s the KQL query that this M query folds to (taken from the View Native Query dialog in the Power Query Editor):
PowerBIDatasetsWorkspace | extend ["Custom"]=["ApplicationContext"]["DatasetId"]
I admit that this is a super-obscure tip but I think it’s fascinating nonetheless, especially given how nested structures are becoming more and more common in the world of big data. It would be great to have similar behaviour in other connectors…
Thanks to my colleague Itay Sagui (whose blog has several posts on Power BI/Azure Data Explorer integration) for this information.