I am a big fan of using Excel cube functions for reporting on Power BI datasets, Analysis Services and Power Pivot: they allow for a lot more layout flexibility than PivotTables when building reports in Excel. However, they do have a reputation for poor performance and part of the reason for this is their chattiness. While Excel does not generate one query for each cell containing a cube function, it is true that a report using cube functions will generate a lot more MDX queries against your Power BI dataset/Analysis Services cube/Power Pivot mode than the equivalent PivotTable. As a result, one way to improve the performance of reports that use Excel cube functions is to optimise them to reduce the number of MDX queries generated.
To understand how to do this you first need to understand how Excel generates the MDX queries needed by cube functions. First of all it looks at the cells containing CubeValue functions on a worksheet and groups them together by the granularity of the data they are requesting; then, for each granularity, it runs one or more MDX queries to get the data it needs, where each query gets data for up to 500 cells. There’s not much you can do to control this behaviour, but in situations where you have multiple fact tables with different granularities there is a trick you can play to reduce the number of queries.
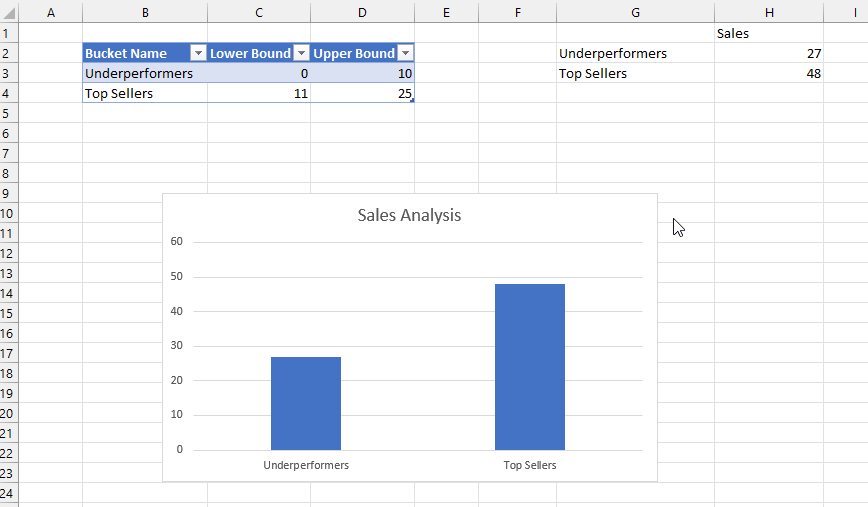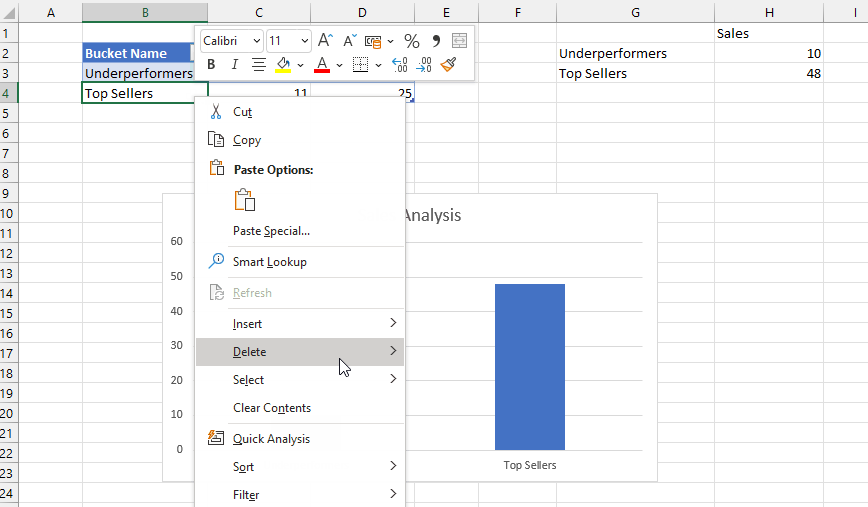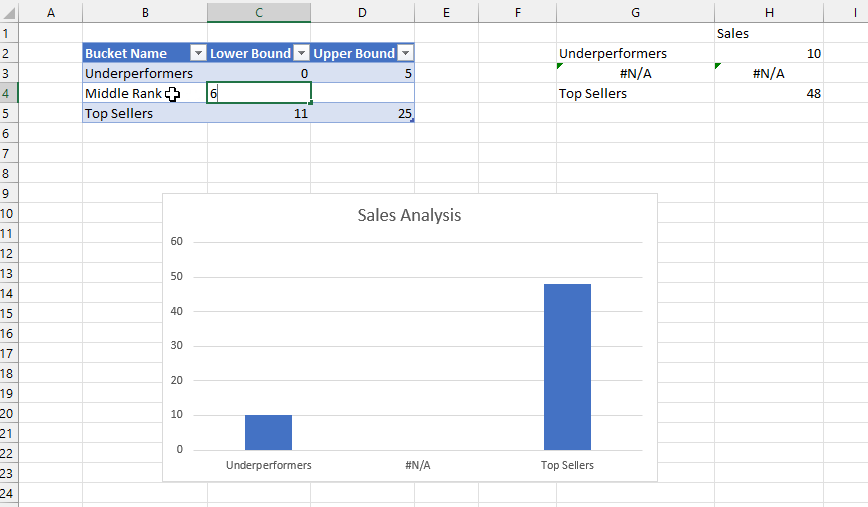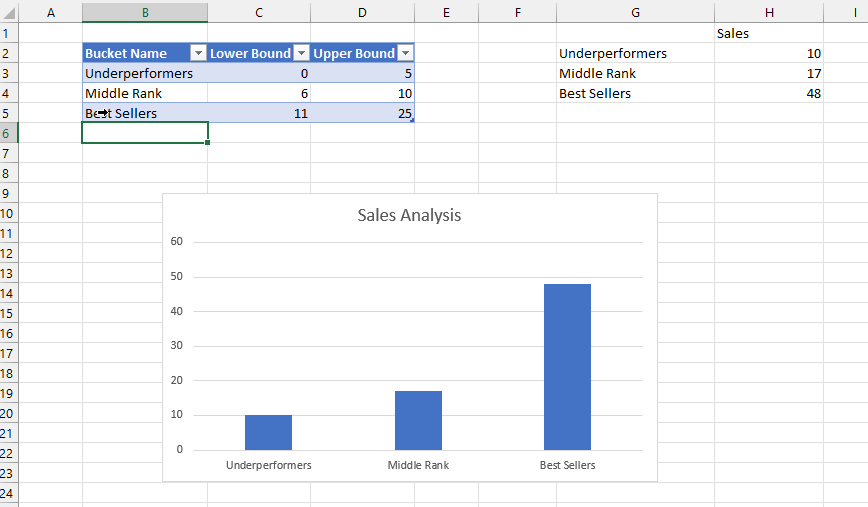
Let’s take a simple example. Consider the following source data:

…loaded into a Power BI dataset with two fact tables, Sales and Targets, and two dimension tables, Product and Country:

Now consider the following report that uses two groups of cube formulas to get the Sales Amount for Apples in the UK and the Target Amount for the UK:

Here are the formulas for these cells:

This worksheet generates two MDX queries for the two different granularities (plus one other MDX query that gets some metadata). The first gets the Sales Amount for Apples in the UK and populates the CubeValue function in cell D3. This query consists of a single MDX tuple whose granularity is Country, Measure and Product:
SELECT
{([Country].[Country].&[UK],[Measures].[Sales Amount],[Product].[Product].&[Apples])}
ON 0
FROM [Model]
CELL PROPERTIES VALUE, FORMAT_STRING, LANGUAGE, BACK_COLOR, FORE_COLOR, FONT_FLAGSThe second gets the Target Amount for the UK and populates the CubeValue function in cell D6. It consists of a single MDX tuple whose granularity is Country and Measure:
SELECT
{([Country].[Country].&[UK],[Measures].[Target Amount])}
ON 0
FROM [Model]
CELL PROPERTIES VALUE, FORMAT_STRING, LANGUAGE, BACK_COLOR, FORE_COLOR, FONT_FLAGSIt is possible to get the same data in a single MDX query and the key to doing so is to make the granularity of the two requests the same. One way of doing this is to edit the contents of cell D6, which at this point contains the following formula to get the Target Amount (in D5) for the UK (in C6) using the CubeValue function:
=CUBEVALUE("CubeFunctionsOptimisationDataset", C6,D5)If you add an extra reference to cell C3, which contains the CubeMember function returning the Product Apples, like so:
=CUBEVALUE("CubeFunctionsOptimisationDataset", C6,D5, C3)Then this results in exactly the same data being returned to Excel and exactly the same data being displayed in the worksheet, but with a single MDX query being generated:
SELECT
{([Country].[Country].&[UK],[Measures].[Target Amount],[Product].[Product].&[Apples]),
([Country].[Country].&[UK],[Measures].[Sales Amount],[Product].[Product].&[Apples])}
ON 0
FROM [Model]
CELL PROPERTIES VALUE, FORMAT_STRING, LANGUAGE, BACK_COLOR, FORE_COLOR, FONT_FLAGSAs you can see, this query now consists of two tuples whose granularity is Country, Measure and Product. The reason this works is because adding the reference to the Product Apples makes no difference to the value returned by the Target Amount measure – which has no relationship with the Product dimension table – but it is enough to fool Excel into thinking that the CubeValue function in cell D6 is making a request at the same granularity as the CubeValue function in cell D3. It is necessary to add a reference to an individual Product, such as Apples, rather than the All Member on Product though.
Another, perhaps more complicated, way of achieving the same result is to leave the formula in cell D6 the same but change the formula in C6 from:
=CUBEMEMBER("CubeFunctionsOptimisationDataset", "[Country].[Country].[All].[UK]")…to use the tuple form of CubeMember to get the combination of Apples and UK:
=CUBEMEMBER("CubeFunctionsOptimisationDataset", {"[Product].[Product].[All].[Apples]","[Country].[Country].[All].[UK]"})Note that when you use this tuple form of CubeMember, putting Apples first in the tuple and Country second results in only the Country name being displayed in the cell, so again the data displayed in Excel is exactly the same.
Reducing the number of MDX queries in this way can improve performance for two reasons: it reduces the number of round trips to the dataset and it gives the Analysis Services engine (in Power BI, Analysis Services or Power Pivot) the chance to get the data needed in a more optimal way than might be possible with multiple queries. I don’t think the technique in this post will make a massive difference to performance but if you do try this, I’m curious to see how much of an improvement you see.