If you’re using Power BI in DirectQuery mode against a SQL Server-related data source (ie SQL Server on-prem, Azure SQL DB or Synapse) you may have noticed a new feature that was released a few weeks ago: query labels that allow you to link a SQL query to the Power BI visual that generated it.
There’s nothing you need to do to enable it – it happens automatically. Here’s an example of a TSQL query generated by a DirectQuery mode dataset with it in:
You can see that an OPTION clause in the query adds a label that contains three GUIDs that identify the dataset, report and visual that the query was generated for. These are the same GUIDs that you’ll see used for this purpose in other places, for example Log Analytics. This post has more details on how you can work out which datasets, reports and and visuals these GUIDs relate to.
As I said, this only works for SQL Server-related sources at the moment, but if you think this would be useful for other sources (and I’m sure you do…) please leave a comment below!
As a postscript to my series on Power BI refresh timeouts (see part 1, part 2 and part 3) I thought it would be useful to document how I was able to simulate a slow data source in Power BI without using large data volumes or deliberately complex M code.
It’s relatively easy to create an M query that returns a table of data after a given delay. For example, this query returns a table with one column and one row after one hour and ten minutes:
let
Source = Function.InvokeAfter(
() => #table({"A"}, {{1}}),
#duration(0, 1, 10, 0)
)
in
Source
Some notes:
I’m using #table to return the table without having to connect to a data source. More details on how to use #table can be found here.
The delay is achieved using the Function.InvokeAfter M function, with the amount of time to wait for specified using #duration
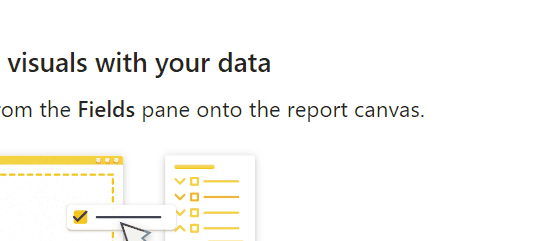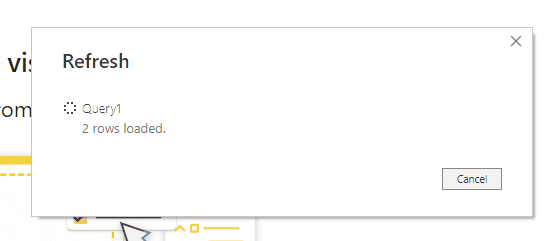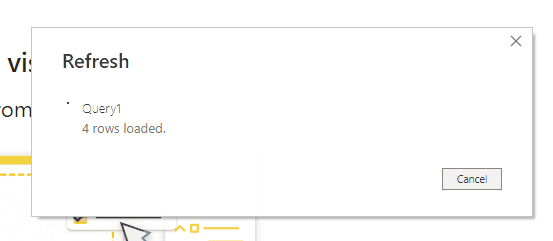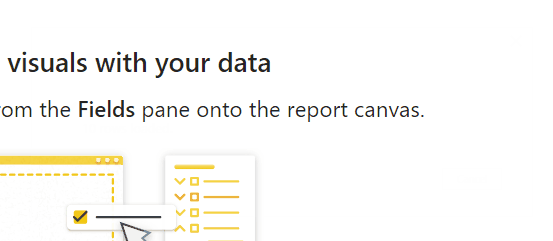
A more interesting problem is how to create an M query that, instead of waiting for a given duration and then returning a table immediately, returns the rows of a table one at a time with a delay between each row. Here’s a query that does that, returning ten rows one second at a time:
Last of all, to simulate a slow SQL Server data source – not being much good at TSQL at all – I borrowed some code from this thread on Stack Overflow to create a function that returns a scalar value after a specified number of seconds:
CREATE FUNCTION [dbo].[ForceDelay](@seconds int) returns int as
BEGIN DECLARE @endTime datetime2(0) = DATEADD(SECOND, @seconds, GETDATE());
WHILE (GETDATE() < @endTime )
SET @endTime = @endTime;
return 1;
END
I showed how to call this function from Power Query using a native SQL query here.
In the first post in this series I showed how any Power BI dataset refresh started via the Power BI portal or API is limited to 2 hours in Shared capacity and 5 hours in Premium capacity, and how you could work around that by running a refresh via Premium’s XMLA endpoint feature. In the second post in this series I showed how some M functions allow you to set timeouts. However, even if you initiate a refresh via the XMLA endpoint you may still get a timeout error and in this post I’ll discuss another reason why: the External Command Timeout.
This property is a hangover from Analysis Services (you can see it documented here). It represents the amount of time the Analysis Services engine inside Power BI will wait to get data from a data source. How it behaves exactly depends on the data source: it may limit the amount of time it takes to get the first row of data from the source or it may limit the amount of time it takes to get all the rows of data. In Power BI Premium it is set to five hours, which means that no single partition can take more than about five hours to refresh. In the first post in this series I worked around this by creating a dataset with multiple partitions, each of which took about an hour to refresh, but when trying to refresh a dataset with a single partition that takes more than five hours I got the following error when trying to refresh from SQL Server Management Studio through the XMLA Endpoint:
The error message here is:
Timeout expired. The timeout period elapsed prior to completion of the operation.. The exception was raised by the IDbCommand interface.
In this case I saw the same error in the Error event in Profiler:
…and in other cases, when testing a different source, I got a different error in Profiler in the Progress Report Error event:
There’s no way to avoid the External Command Timeout. Instead, what you need to do is either change your partitioning strategy so each partition refreshes in under five hours or tune your data source, M code or gateway (if you’re using one) so that data is returned to Power BI faster.
In Shared capacity I believe the External Command Timeout is set to two hours (again, to match the overall refresh timeout) but it’s much less important there because you can’t create partitions manually (the only way a dataset in Shared can be partitioned is by setting up incremental refresh) and there’s no XMLA Endpoint so there’s no way to work around the two hour overall refresh limit anyway.
[Thanks, as always, to Akshai Mirchandani for a lot of the information in this post]
In the first post in this series I showed how the Power BI Service applies a limit on the total amount of time it takes to refresh a dataset in the Power BI Service, except when you initiate your refresh via an XMLA Endpoint. In this post I’ll look at the various timeouts that can be configured in Power Query functions that are used to access data.
Every time a Power BI Import mode dataset connects to a data source it goes through a Power Query query, and inside the code of that Power Query query will be an M function that connects to a specific type of data source. Most – but not all – of these M functions have the option to set timeouts. The M functions that connect to relational databases (for example Sql.Database which is used to connect to SQL Server-related sources, or Odbc.DataSource which is used to connect to ODBC sources) typically allow you to configure two types of timeout:
A connection timeout, which specifies how long to wait when trying to open a connection to the data source
A command timeout, which specifies how long the query to get data from the source is allowed to run
Some other functions have other timeouts more appropriate to the data source they access: for example Web.Contents and OData.Feed have a Timeout property for the HTTP requests they make behind the scenes. Other functions (for example Excel.Workbook) have no timeout-related properties that you can set at all. You should check the documentation , either online or using the #shared intrinsic variable in the Power Query Editor, to see what options are available and what the default timeouts are.
Here’s a simple example of how to set a timeout when connecting to SQL Server. First of all, I created a scalar function called ForceDelay in TSQL that returns a value of 1 after a specified number of seconds, so the query:
select [dbo].[ForceDelay](10) as MyColumn
…takes 10 seconds to run.
When you connect to SQL Server in Power BI/Power Query you can paste a SQL query in the connection dialog under Advanced Options; when you do so you’ll also see the option to set the command timeout in minutes:
Here’s the M code generated when you use the SQL query above, set the Command timeout to 1 minute and click OK:
let
Source = Sql.Database(
"localhost",
"AdventureWorksDW2017",
[
Query
= "select [dbo].[ForceDelay](10) as MyColumn",
CommandTimeout = #duration(
0,
0,
1,
0
)
]
)
in
Source
Notice that the CommandTimeout option has been set on the Sql.Database function, and that the value passed to it is a duration of one minute defined using #duration. Since the SQL query takes 10 seconds to run and the timeout is 1 minute, it runs successfully.
However, if you set the CommandTimeout option to 5 seconds like so:
let
Source = Sql.Database(
"localhost",
"AdventureWorksDW2017",
[
Query
= "select [dbo].[ForceDelay](10) as MyColumn",
CommandTimeout = #duration(
0,
0,
0,
5
)
]
)
in
Source
…then the query will take longer that the timeout and you’ll see the following error in the Power Query Editor:
The error message is:
DataSource.Error: Microsoft SQL: Execution Timeout Expired. The timeout period elapsed prior to completion of the operation or the server is not responding.
If you hit the timeout when refreshing in the main Power BI window you’ll see the same message in the refresh dialog box:
So, as you can see, if you are working with large data volumes or slow queries you will need to be aware of the default timeouts set in the M functions you’re using and alter them if need be.
If you’re working with a large Power BI dataset and/or a slow data source in Import mode it can be very frustrating to run into timeout errors after you have already waited a long time for a refresh to finish. There are a number of different types of timeout that you might run into, and in this series I’ll look at a few of them and discuss some of the ways you can work around them.
In this post I’ll look at one of the most commonly-encountered timeouts: the limit on the maximum length of time an Import mode dataset refresh can take. As documented here these limits are:
Two hours for an import-mode dataset in Shared capacity
Five hours for an import-mode dataset in a Premium or PPU capacity
If you are using Premium you can connect to your dataset using SQL Server Profiler and run a trace when the refresh starts and you’ll see the timeout set as a property of the TMSL command that runs the refresh (18000 seconds = 5 hours):
Here’s an example of the message you will see in the Refresh History dialog if your dataset refresh takes more than five hours in PPU:
Once again you get more details in a Profiler trace. When the refresh times out you’ll see an Error event with long message that starts with the following text:
Timeout expired. The timeout period elapsed prior to completion of the operation.. The exception was raised by the IDbCommand interface. The command has been canceled..
There is a way to work around this limit if you’re using Premium or PPU: it only applies to refreshes (scheduled or manual) that you start from the Power BI portal or via the REST API. If you start your refresh by running a TMSL script via the XMLA Endpoint (for example via SQL Server Management Studio or from PowerShell) then the limit does not apply. This is because you’re executing your own TMSL script rather than having the Power BI Service execute its own refresh command – with a timeout set – like the one shown in the screenshot above.
For example, here’s the same dataset from the screenshot above but refreshed successfully from SQL Server Management Studio (notice the Type column says “Via XMLA Endpoint”) and with a duration of just over five hours:
There are a couple of blog posts out there showing how you can implement a refresh strategy using the XMLA Endpoint; this post from Marc Lelijveld and Paulien van Eijk is a great example of how to do this using Azure Automation and Azure Data Factory.
You should also consider tuning any refresh that takes a long time and it could be that after tuning it you fall well within the two/five hour limit. There are a lot of things to consider when tuning dataset refresh; I did a conference session on this topic last year (you can watch the recording here) covering issues like data modelling, query folding in Power Query and the use of dataflows but it doesn’t cover everything and I have learned a lot even since then. In my opinion one of the most important things you can do to improve refresh performance for very large Import datasets is to partition your fact tables and increase the amount of parallelism, as I describe here. One customer I worked with was able to reduce their refresh time from four hours down to one hour using this technique:
As I said, though, there are many different types of timeout that you may encounter – so even if you refresh via the XMLA Endpoint it may still time out for another reason.
In my quest to check out every last bit of obscure Power Query functionality, this week I looked into the ContextInfo option on the Sql.Database and Sql.Databases M functions. This option allows you to set CONTEXT_INFO in SQL Server (see here for a good article explaining what this is) and here’s an example of how to use it:
let
Source = Sql.Database(
"localhost",
"AdventureWorksDW2017",
[
Query = "SELECT * FROM DIMDATE",
ContextInfo = Text.ToBinary(
"Hello"
)
]
)
in
Source
This Power Query query runs a simple SQL SELECT statement against the SQL Server Adventure Works DW 2017 database. Note that since you need to pass a binary value to the ContextInfo option, in this example I had to use the Text.ToBinary function to convert my text to binary.
Here’s what happens in SQL Server when this Power Query query is run:
Here’s a simple example of how to retrieve this data on the SQL Server side:
SELECT session_id, login_time, program_name, context_info
FROM sys.dm_exec_sessions
WHERE session_id=57
I’ll leave it to the SQL Server experts to decide what this can be used for and no doubt to complain that it would be more useful to support SESSION_CONTEXT too – although I’ve heard that might already be used for something, so I need to do more research here…
Back in September I posted about a few new Power BI-related books I was given to review for free; that post led to me getting sent another freebie book, “Extending Power BI with Python and R”, by Luca Zavarella (buy it from Amazon UK here). I found this book particularly interesting because I know very little about Python or R, but I also know that this is a really hot topic for many people and I was curious to know what problems using these languages in Power BI might solve.
I can’t comment on the quality of the Python and R advice (although I’m pretty sure Luca knows what he’s writing about), but from the point of view of a Power BI developer the book does a good job of explaining how using them allows you to do things that are difficult or impossible otherwise. There are chapters on regular expressions, calling APIs, using machine learning models and advanced visualisations. I haven’t seen any other books, videos or blog posts that cover these topics in such detail, so if you have some Python or R skills and want to make use of them in Power BI this book seems to be a good bet.
Over the past few years I’ve blogged and presented extensively on the subject of Power Query’s data privacy settings (see here for a post with links to all this content). I thought I knew everything there was to know… but of course I didn’t, and I’ve recently learned about an issue that can cause mysterious errors.
As always it’s easiest to show an example of how it can occur. Here’s a table of airport names taken from the TripPin public OData feed:
Note how the Location column contains nested values of data type Record, and note that I have not expanded this column.
Here’s another query with sales data for these airports coming from Excel:
Now let’s say we want to join these two queries together using a Merge operation in the Power Query Editor. When you do this, because you are combining data from two different sources and because OData supports query folding, you will be prompted to set data privacy settings on these sources (unless you have already done so at some point in the past) because a Merge could result in data being sent from Excel to the OData source.
If you set the data privacy levels to Private on each source, like so:
…you are telling Power Query that it should never send data from these sources to any other source. As a result, Power Query has to load the data from both sources, buffer that data in memory, and do the Merge inside its own engine.
When you do the Merge everything looks normal at first:
But when you expand the Airports column you’ll see that the nested values in the Location column have been turned into the text “[Record]” and as a result can no longer be expanded.
This is because Power Query has had to buffer the values in the Airports query but it is unable to buffer nested values (I wrote about this here).
There are two ways to fix this. First of all, you can change the data privacy settings or turn them off completely. I don’t recommend turning them off completely because this is only possible in Power BI Desktop and not in the Power BI Service, and even changing the data privacy settings can lead to some unexpected issues later on. For example, if you set the data privacy levels for both sources to Public like so:
…then no buffering is needed (because data can now be sent from one source to another) and the nested values in the Location field can be expanded:
…and of course you do so:
However, people always forget that you have to set your data privacy levels again after publishing your dataset to the Power BI Service. And if you or someone else subsequently sets the data privacy levels back to Private you’ll get the following error in the output of the query:
The error message here is:
“Expression.Error: We cannot convert the value “[Record]” to type Record.”
Depending on the data type of the nested field you might get:
“Expression.Error: We cannot convert the value “[Table]” to type Table.”
or
“Expression.Error: We cannot convert the value “[List]” to type List.”
…instead.
The second way to fix the problem is easier and probably safer: you just need to expand the Location column before the Merge operation instead of after it. That way there are no nested fields present when the Merge takes place so all the values can be buffered. Here’s what the Airports table looks like after the Location column has been expanded, before the Merge:
…and here’s the output of the Merge even when the data privacy levels for both sources are set to Private:
In the last few months the following issue has been escalated up to the Power BI CAT team several times: customers have deployed reports into production and then found that users are able to see data they should not be allowed to see by using the “Show data point as a table” feature. The question is: is this a security hole? It isn’t, and in this blog post I’ll explain why and how you should think about security as something that happens on the dataset and not in the report.
Here’s a simple example of the problem. Say you have a dataset with the following table in it:
It contains sales data but the text in the Comments field is sensitive and should not be visible to everyone. If you have a report with a matrix visual in it, put Employee on columns and drag the Revenue field into values and sum it up (ie create an implicit measure rather than defining an explicit measure) like so:
…then an end user will be able to view the report, select a cell in the visual, right click and select “Show data point as a table” and see a table that contains unaggregated data including some of the fields from the underlying table that go to make up that value – including the Comments field.
Ooops! Of course it’s bad when an end user sees something they shouldn’t but this isn’t Power BI’s fault. As a Power BI developer it’s important to understand that visibility and security are not the same thing and that data security is something that is defined on a dataset and not in a report. You need to use features such as row-level security and object-level security to stop users seeing data they should not be allowed to see – or you should not import that data into your dataset in the first place. You can stop the “Show data point as table” option from appearing by changing the visual you use in your report or by using an explicit measure (ie one defined using a DAX expression), but that’s still not secure and there’s no guarantee that users would not be able to see the same data some other way.
In our example, with object-level security set up to deny access to the Comments field you can be sure that users will not be able to see that data unless they have permission. When viewing the report via a role with OLS defined then the Comments field will not appear when you use “Show data point as a table”:
If you’re working in Power BI Desktop you may sometimes find that your visuals error with the message “Couldn’t load the data for this visual. The operation was cancelled because of locking conflicts”:
Why is this happening? If you’re an old Analysis Services person like me you may be familiar with the error – the basic problem is the same – but here’s a simple explanation. If you’re making changes to your dataset (for example editing the DAX for a measure) in Power BI Desktop then Power BI has to wait for any DAX queries, that is to say the queries that get the data for your visuals, that are currently running to finish before it can save those changes. However if it has to wait too long to do this then it will kill any queries still running so it can go ahead and commit those changes, and when it does so you’ll see the “locking conflicts” error.
I was able to recreate this error by creating a DirectQuery dataset with a single table based linked to a SQL query that takes one minute to run, building the report shown in the screenshot above, and then creating a new measure when the visual on the left was rendering. Even then it didn’t error consistently – which I guess is a good thing!
Now you know the cause, the next question is what can you do to avoid it? Since the problem is caused by long-running DAX queries the answer is to tune your queries to make them faster. To be honest, if you have queries that are slow enough to cause this error you already have a usability issue with your report – most DAX queries should run for no more than a couple of seconds.