As a postscript to my series on Power BI refresh timeouts (see part 1, part 2 and part 3) I thought it would be useful to document how I was able to simulate a slow data source in Power BI without using large data volumes or deliberately complex M code.
It’s relatively easy to create an M query that returns a table of data after a given delay. For example, this query returns a table with one column and one row after one hour and ten minutes:
let
Source = Function.InvokeAfter(
() => #table({"A"}, {{1}}),
#duration(0, 1, 10, 0)
)
in
Source
Some notes:
- I’m using #table to return the table without having to connect to a data source. More details on how to use #table can be found here.
- The delay is achieved using the Function.InvokeAfter M function, with the amount of time to wait for specified using #duration
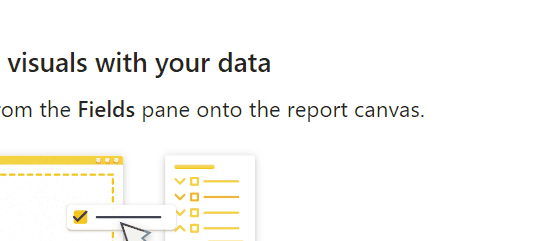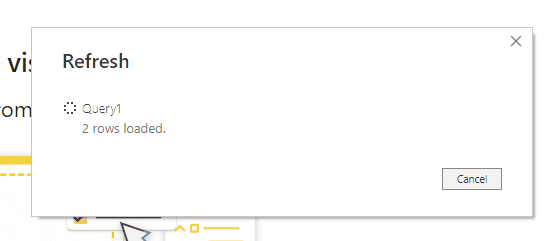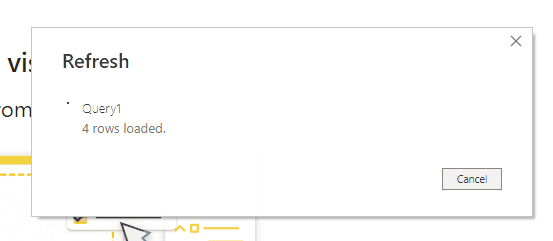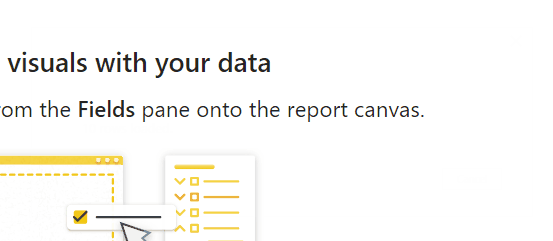
A more interesting problem is how to create an M query that, instead of waiting for a given duration and then returning a table immediately, returns the rows of a table one at a time with a delay between each row. Here’s a query that does that, returning ten rows one second at a time:
let
NumberOfRows = 10,
DaysToWait = 0,
HoursToWait = 0,
MinutesToWait = 0,
SecondsToWait = 1,
Source = #table(
{"A"},
List.Transform(
{1 .. NumberOfRows},
each Function.InvokeAfter(
() => {1},
#duration(
DaysToWait,
HoursToWait,
MinutesToWait,
SecondsToWait
)
)
)
)
in
Source
Last of all, to simulate a slow SQL Server data source – not being much good at TSQL at all – I borrowed some code from this thread on Stack Overflow to create a function that returns a scalar value after a specified number of seconds:
CREATE FUNCTION [dbo].[ForceDelay](@seconds int) returns int as BEGIN DECLARE @endTime datetime2(0) = DATEADD(SECOND, @seconds, GETDATE()); WHILE (GETDATE() < @endTime ) SET @endTime = @endTime; return 1; END
I showed how to call this function from Power Query using a native SQL query here.
























