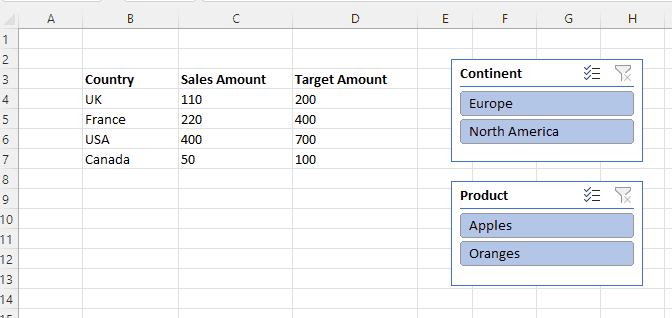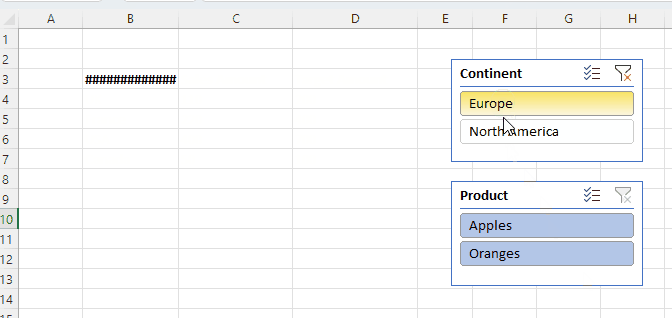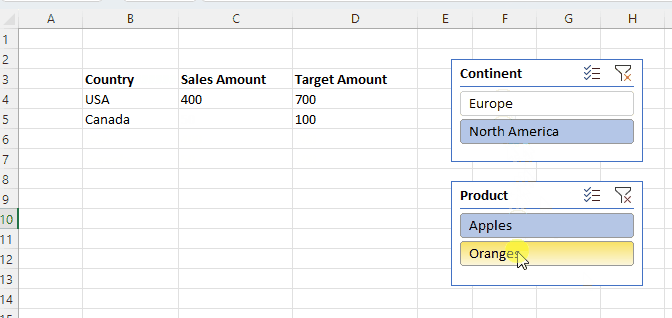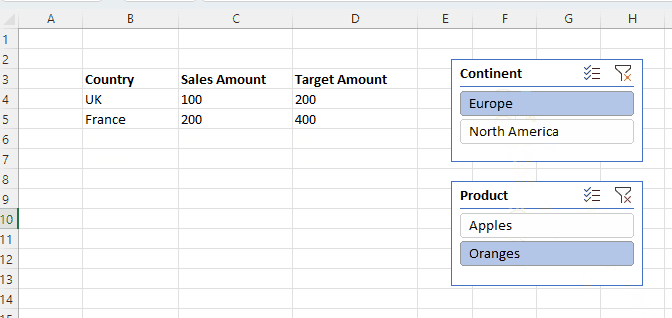
If you’re tuning refresh for a Power BI Import mode dataset one of the areas you’ll be most interested in is throughput, that is to say how quickly Power BI can read data from the data source. It can be affected by a number of different factors: how quickly the data source can return data; network latency; the efficiency of the connector you’re using; any transformations in Power Query; the number of columns in the data and their data types; the amount of other objects in the same Power BI dataset being refreshed in parallel; and so on. How do you know if any or all of these factors is a problem for you? It’s a subject that has always interested me and now that Log Analytics for Power BI datasets is GA we have a powerful tool to analyse the data, so I thought I’d do some testing and write up my findings in a series of blog posts.
The first thing to understand is what events there are in Log Analytics that provide data on throughput. The events to look at are ProgressReportBegin, ProgressReportCurrent and ProgressReportEnd (found in the OperationName column), specifically those with OperationDetailName ExecuteSql, ReadData and Tabular Refresh. Consider the following KQL query that looks for at this data for a single refresh and for a single partition:
let RefreshId = "e5edc0de-f223-4c78-8e2d-01f24b13ccdc";
let PartitionObjectPath = "28fc7514-d202-4969-922a-ec86f98a7ea2.Model.TIME.TIME-ffca8cb8-1570-4f62-8f04-993c1d1d17cb";
PowerBIDatasetsWorkspace
| where TimeGenerated > ago(3d)
| where XmlaRequestId == RefreshId
| where XmlaObjectPath == PartitionObjectPath
| where OperationDetailName == "ExecuteSql" or OperationDetailName == "ReadData" or OperationDetailName == "TabularRefresh"
| project XmlaObjectPath, Table = split(XmlaObjectPath,".", 2)[0], Partition = split(XmlaObjectPath,".", 3)[0],
TimeGenerated, OperationName, OperationDetailName, EventText, DurationMs, CpuTimeMs, ProgressCounter
| order by XmlaObjectPath, TimeGenerated asc;Some notes on what this query does:
- All the data comes from the PowerBIDatasetsWorkspace table in Log Analytics
- I’ve put an arbitrary filter on the query to only look for data in the last three days, which I know contains the data for the specific refresh I’m interested in
- An individual refresh operation can be identified by the value in the XmlaRequestId column and I’m filtering by that
- An individual partition being refreshed can be identified by the value in the XmlaObjectPath column and I’m filtering by that too
- The value in the XmlaObjectPath column can be parsed to obtain both the table name and partition name
- The query filters the events down to those mentioned above
Here are some of the columns from the output of this query, showing data for the refresh of a single table called TIME with a single partition:

Some more notes on what we can see here:
- The TimeGenerated column gives the time of the event. Although the time format shown here only shows seconds, it actually contains the time of the event going down to the millisecond level – unlike in a Profiler trace, where time values are rounded to the nearest second and are therefore lot less useful.
- The first event returned by this query is a ProgressReportBegin event of type TabularRefresh which marks the beginning of the partition refresh.
- As I blogged here, after that are a pair of ProgressReportBegin/End events of type ExecuteSql. The value in the DurationMs column tells you how long it takes for the data source (which includes time taken by the actual query generated against the data source and any Power Query transformations) to start to return data – which was, in this case, 6016 milliseconds or 6 seconds.
- Next there is a ProgressReportBegin event which indicates the beginning of data being read from the source.
- After that there are a series of ProgressReportCurrent events which mark the reading of chunks of 10000 rows from the source. The ProgressCounter column shows the cumulative number of rows read.
- Next there is a ProgressReportEnd event that marks the end of the data read. The ProgressCounter shows the total number of rows read (which must be less than 10000 rows greater than the value in the ProgressCounter column for the previous ProgressReportCurrent event); the DurationMs column shows the total time taken to read the data. In this case 86430 rows of data were read in 1.4 seconds.
- Finally there is a ProgressReportEnd event of type TabularRefresh, the pair of the first event shown returned. It not only shows the total amount of time taken and the CPU time used to refresh the partition (which includes other operations that are nothing to do with throughput such as compressing data and building dictionaries) in the DurationMs column, as I blogged here it also includes data on the CPU and peak memory used by Power Query during the refresh. In this case the total refresh time was 7.6 seconds, so not much more than the time taken to read the data.
Clearly there’s a lot of useful, interesting data here, but how can we analyse it or visualise it? Stay tuned for my next post…