Excel workbooks are one of the slowest data sources you can use with Power Query in Excel or Power BI. Reading small amounts of data from small workbooks is usually fast; reading large amounts of data from large workbooks can be very slow. But what about reading small amounts of data from large Excel workbooks? I did some tests and it turns out that performance can vary a lot depending on where your data is in the workbook and how that workbook is structured.
[Note: in this post I’ll be looking at .xlsx files, rather than other Excel formats like .xls and .xlsb; Excel files stored on a local disk and accessed via the File.Contents M function rather than stored in SharePoint or any other location; data read from Excel tables rather than direct from the worksheet; and Power Query in Power BI. Other scenarios may perform differently.]
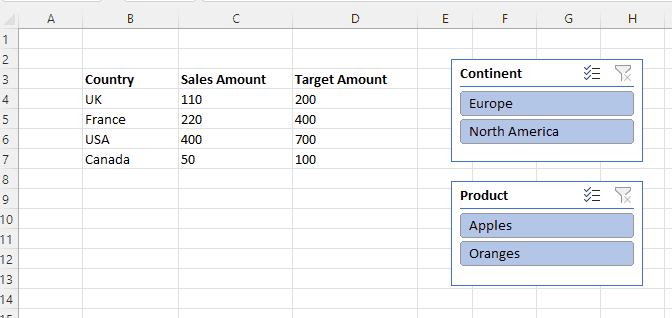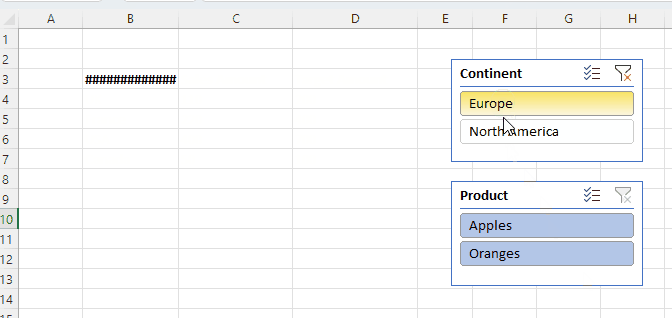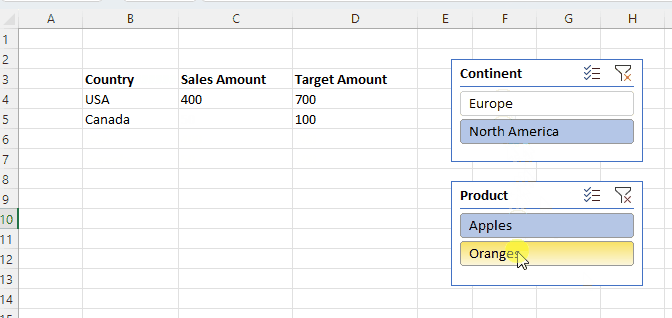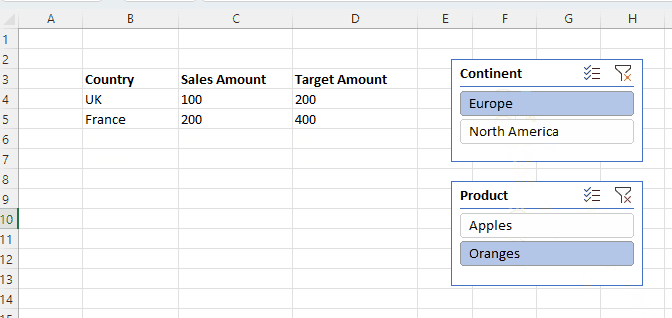
Let’s see a simple example to illustrate what I found out. I created a new Excel workbook with one worksheet in and put a small table of data on it:

At this point the workbook’s size was 11KB. I then opened Power BI Desktop and created a Power Query query that read this table of data from the Excel workbook:
let
Source = Excel.Workbook(File.Contents("C:\MyWorkbook.xlsx"), null, true),
Sales_Table = Source{[Item="Sales",Kind="Table"]}[Data],
#"Changed Type" = Table.TransformColumnTypes(Sales_Table,{{"Product", type text}, {"Sales", Int64.Type}})
in
#"Changed Type"Then I used this technique to measure how long it took to load the data from Excel into Power BI. Unsurprisingly, it was extremely fast: 63ms.
Then I added a new worksheet to the workbook, copied the same table onto it, added a large amount of random numbers underneath using the following Excel formula, and then copied and pasted the values returned by the formula over the output of the formula:
=RANDARRAY(9999,300)
Doing this meant the size of the workbook grew to 43MB. I then created a new Power Query query in Power BI Desktop, identical to the one above except that it connected to the new table. This time the query took 4918ms – almost 5 seconds.
Interestingly, even with the second worksheet with all the data on was added, the first query above (on the worksheet with no other data on) was still fast. I also tested refreshing a Power BI dataset that connected to two identical small tables on different worksheets in the same workbook, both with large amounts of other data on as in the second scenario above, and the performance of both queries was only slightly slower: it was clear two Power Query queries can read data from the same Excel workbook in parallel.
So: reading a small amount of data from a table on a worksheet with a large amount of other data on it is very slow.
What can we learn from this? Well, if you can influence the structure and layout of the Excel workbooks you are using as a data source – and that’s a big if, because in most cases you can’t – and you only need to read some of the data from them, you should put the tables of data you are using as a source on separate worksheets and not on the same worksheet as any other large ranges or tables of data.
It turns out that when the Power Query Excel connector reads data from an .xlsx file it can deserialise just some of the data in it rather than the whole thing, but what it can and can’t avoid deserialising depends a lot on the structure of the workbook and how the data is stored within the workbook .xlsx file. If you’re quick you can even see how much data is being read in Power BI Desktop in the refresh dialog:

You can also use Process Monitor, as I describe here, to see how much data is being read from any file used by Power Query.
Performance also depends on which application generated the .xlsx file (it’s not just Excel that creates .xlsx files, because other applications export data to .xlsx format without using Excel) or even which version of Excel saved the .xlsx file. This is because the same data can be stored in an .xlsx file in different ways, some of which may be more efficient to read than others. I found this blog post by Brendan Long on the .xlsx file format was very clear and it helped me understand how Power Query might go about reading data from an .xlsx file.
[Thanks to Curt Hagenlocher of the Power Query team for answering some of my questions relating to this post]