I love Excel as an alternative to Power BI reports, especially now that Excel Online allows you to interact with browser-based Excel reports that use Power BI datasets or the Excel Data Model (aka Power Pivot) as a source. After all, why try to recreate a PivotTable in a Power BI report when you can give your users an actual PivotTable? You can publish Excel reports to Power BI and view them there; however if you want to share these reports using OneDrive for Business, outside Power BI, you’ll need to think carefully about how you do so before you allow other people to view the report.
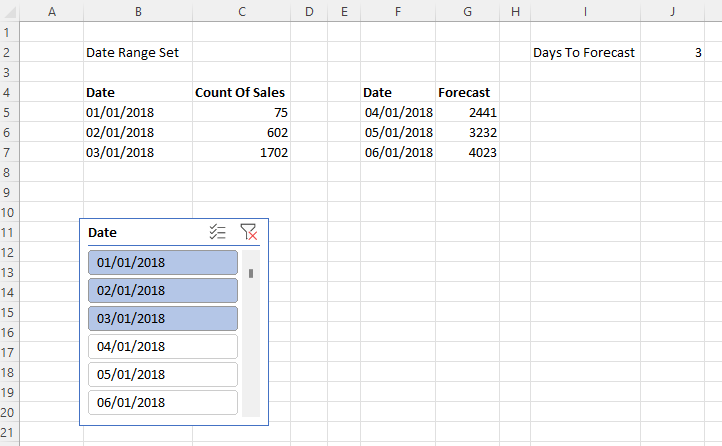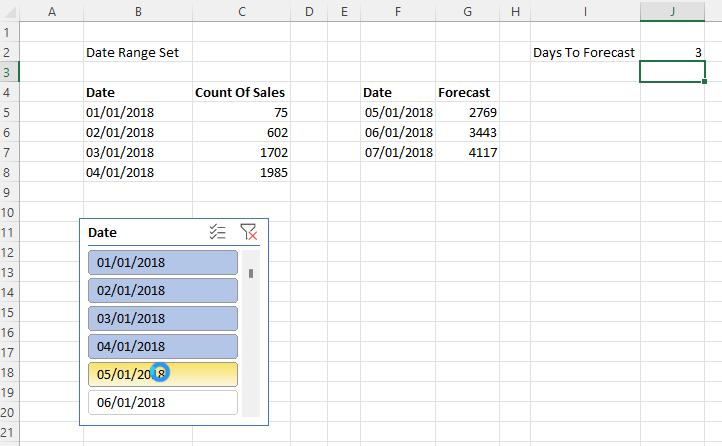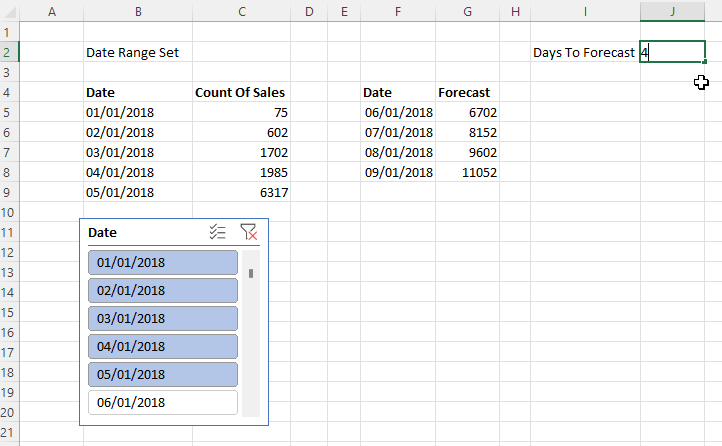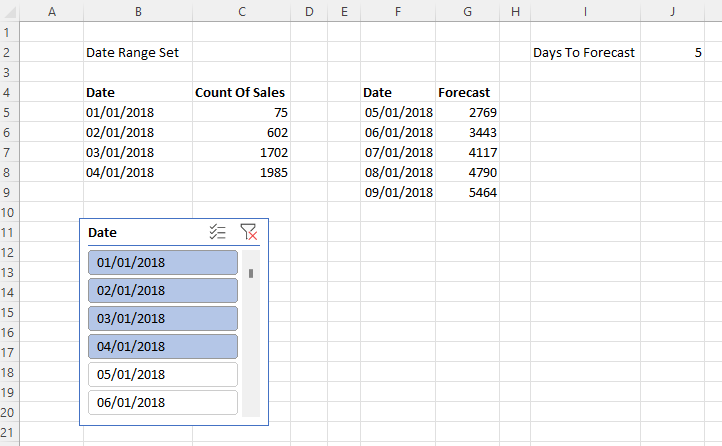
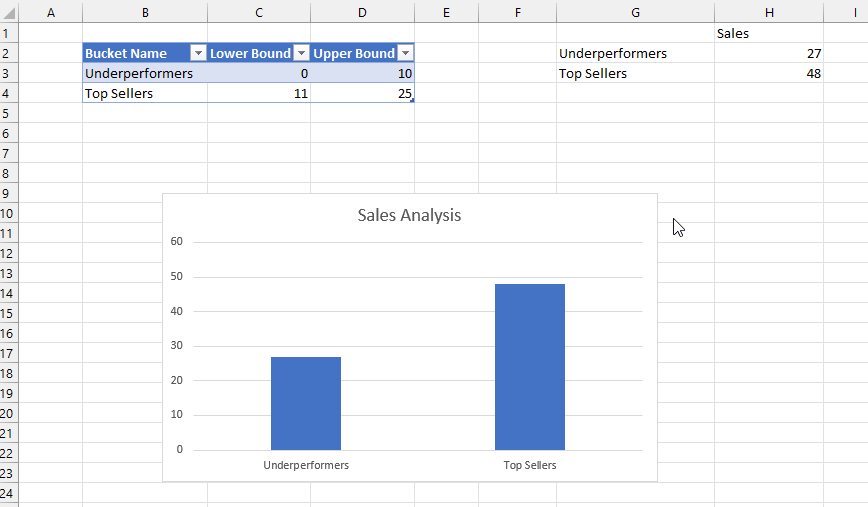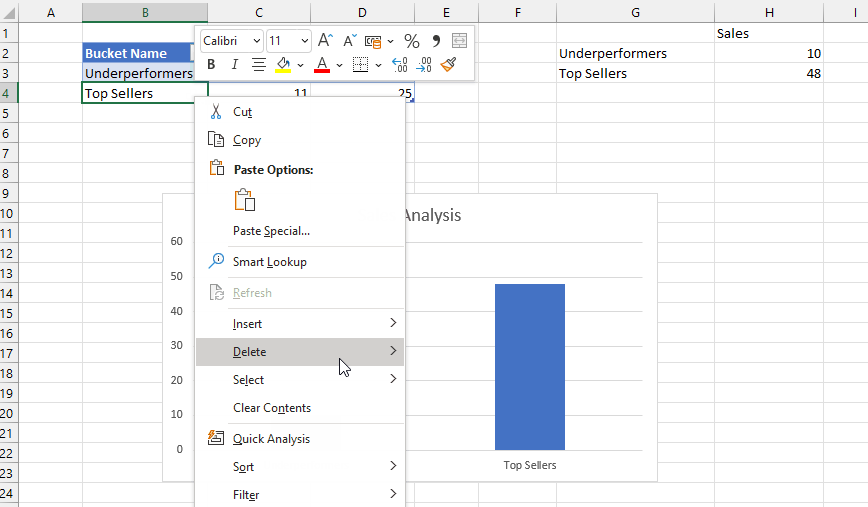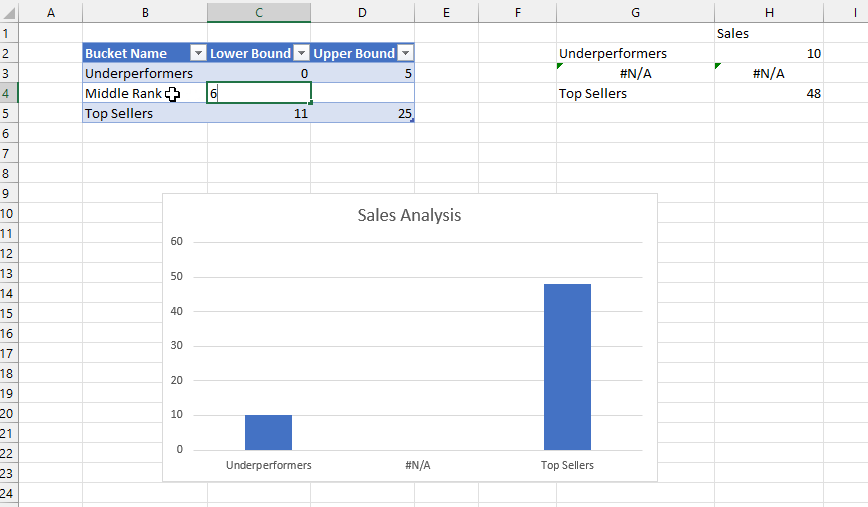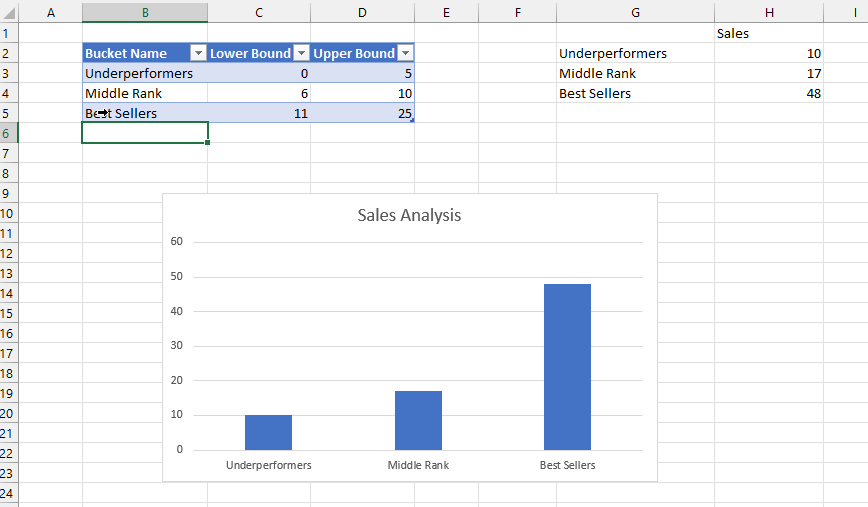
To illustrate the problem I used Power Pivot to load some data into the Excel Data Model, built a simple report with a PivotTable and PivotChart, saved it to OneDrive for Business and then opened it in the browser with Excel Online. As you can see it’s possible to interact with the report in the browser, changing slicers and moving fields around in the PivotTable and PivotChart field lists:

So far so good. However, an Excel file saved to OneDrive for Business is a shared document – and any changes that one user makes are immediately visible to all other users who have access with full Edit permissions. This means that if you change a slicer and someone else is viewing my report at the same time, they will see the slicer change too in real-time. This may be useful in scenarios where you are collaborating with someone on the same report and want them to see your changes, but in most cases this is not desirable behaviour for a report. Here’s an example with the same Excel report open side by side in Chrome and Edge:

How can you stop this happening? One option is to use View mode. When an Excel workbook is in View mode a user can interact with slicers and move fields around in the PivotTable without these changes affecting other users and without these changes being saved; they cannot make most other changes such as entering values in cells. If users do have full Edit permissions they can always switch to View mode using the dropdown menu in the top right corner of the screen:

You can also use the Protect Workbook option to make sure users open the workbook in View mode by default. However there is always the danger that if a user has Edit permissions they will switch to Edit mode and make unwanted changes, so as a result it’s better to share the workbook without Edit permissions using the “Can View” option described here so they can only open the workbook in View mode:

There is another option: using an Embed link. To get this, click on the File menu in Excel Online and then on the backstage view select Share and then Embed:

As the UI suggests, this option is intended for scenarios where you want to embed your workbook in another application; it’s similar to View mode but a bit more restrictive. In the Embed dialog that opens you can choose which parts of the workbook to share, whether grid lines are shown and other useful options:

Here you need to select the “Let people sort and filter” option otherwise your users won’t be able to use the slicers. Next, copy the code from the “Embed code” box and paste into your favourite text editor so you can extract the URL in the src tag – this is the URL you should give to your users. When a user opens an Excel report using a link generated in this way they won’t see the Excel ribbon at all; they can interact with slicers but can’t get access to the PivotTable fields pane and so won’t be able to move fields around, for example changing what is on rows or columns. I think this gives the best experience for end users who just want to view an Excel report in the browser.

Note that this does not replace normal OneDrive for Business sharing and permissions though: you’ll still need to share the report with your users, ideally with “Can View” permissions as described above. If your Excel report connects back to a Power BI dataset you also need to ensure that your users have the appropriate permissions on that dataset, which means they’ll either need to be at least a Member in the workspace the dataset is stored in or have Build permissions.