[This post was originally published on the official Power Query blog, which has now been taken down. I’m republishing all my posts there to this blog to ensure the content remains available.]
Query folding is generally a good thing in Power Query: pushing transformations back to the data source means they almost always perform better. That’s not always the case though and sometimes you need to stop query folding taking place to improve performance. In the past there has been no easy way to do this: you could use the Table.Buffer M function but this also buffers an entire table into memory, which can lead to other, different performance problems; you could also add a transformation that you know doesn’t fold, such as adding an index column to your table, but again this could involve a performance penalty and what’s more if future versions of Power Query are able to fold the transformation then this approach will not work anymore. Now, however, there is a new M function called Table.StopFolding that is guaranteed to stop query folding taking place with no other side effects.
Here’s a simple example of how to use it. Consider the following M query which connects to SQL Server, gets data from the DimProductCategory table in the AdventureWorksDW2017 database and filters it so only the rows where the ProductCategoryKey column is greater than two are returned:
let
Source = Sql.Database(
"localhost",
"AdventureWorksDW2017"
),
dbo_DimProductCategory = Source
{
[
Schema = "dbo",
Item = "DimProductCategory"
]
}
[Data],
#"Filtered Rows" = Table.SelectRows(
dbo_DimProductCategory,
each [ProductCategoryKey] > 2
)
in
#"Filtered Rows"Here’s the SQL query generated by Power Query for this:
select [_].[ProductCategoryKey],
[_].[ProductCategoryAlternateKey],
[_].[EnglishProductCategoryName],
[_].[SpanishProductCategoryName],
[_].[FrenchProductCategoryName]
from [dbo].[DimProductCategory] as [_]
where [_].[ProductCategoryKey] > 2As you can see, the filter has been folded and the WHERE clause of the SQL query contains the filter on ProductCategoryKey.
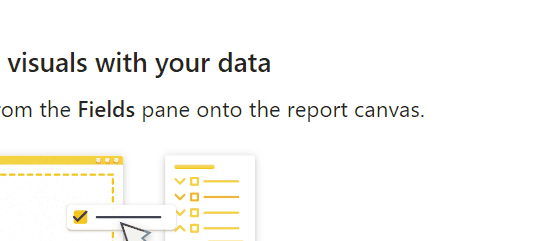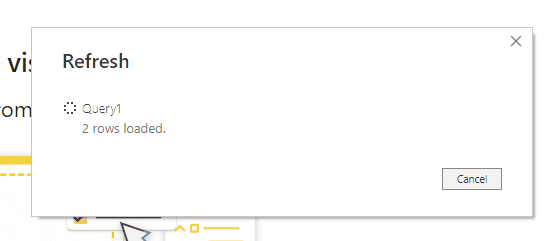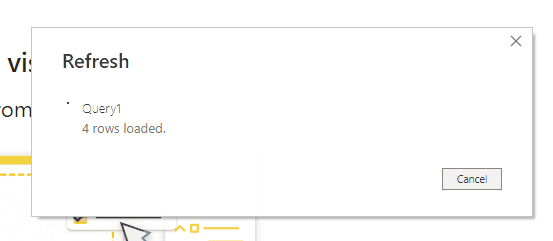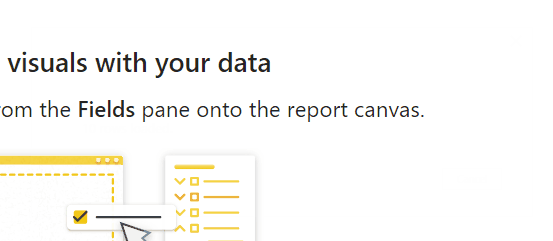
To stop query folding taking place for this filter transformation you can add an extra step to the M code of your query using the Table.StopFolding function like so:
let
Source = Sql.Database(
"localhost",
"AdventureWorksDW2017"
),
dbo_DimProductCategory = Source
{
[
Schema = "dbo",
Item = "DimProductCategory"
]
}
[Data],
PreventQueryFolding
= Table.StopFolding(
dbo_DimProductCategory
),
#"Filtered Rows" = Table.SelectRows(
PreventQueryFolding,
each [ProductCategoryKey] > 2
)
in
#"Filtered Rows"The SQL query generated is now as follows, with no WHERE clause:
select [$Ordered].[ProductCategoryKey],
[$Ordered].[ProductCategoryAlternateKey],
[$Ordered].[EnglishProductCategoryName],
[$Ordered].[SpanishProductCategoryName],
[$Ordered].[FrenchProductCategoryName]
from [dbo].[DimProductCategory] as [$Ordered]
order by [$Ordered].[ProductCategoryKey]The query result is still the same but the filter is not longer being folded back to SQL Server. Instead all the data is being returned to Power Query and the filter is taking place there.