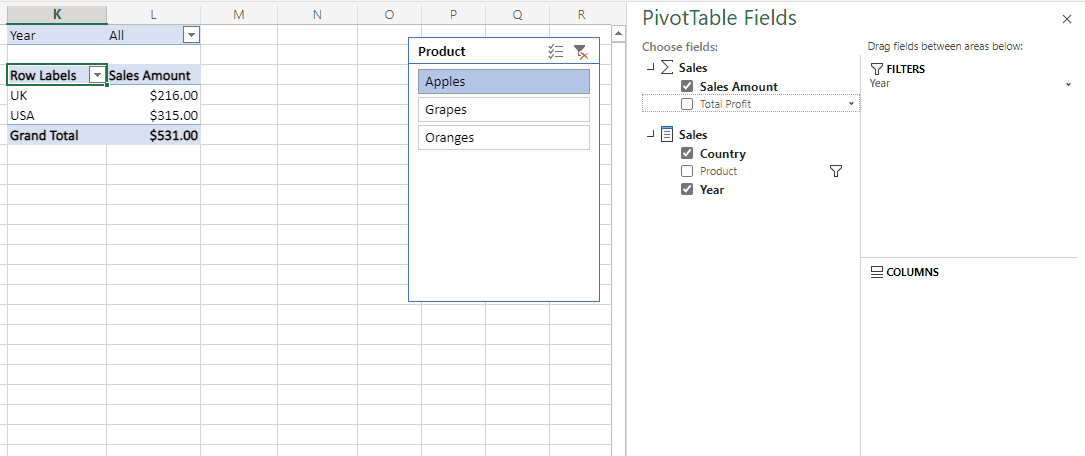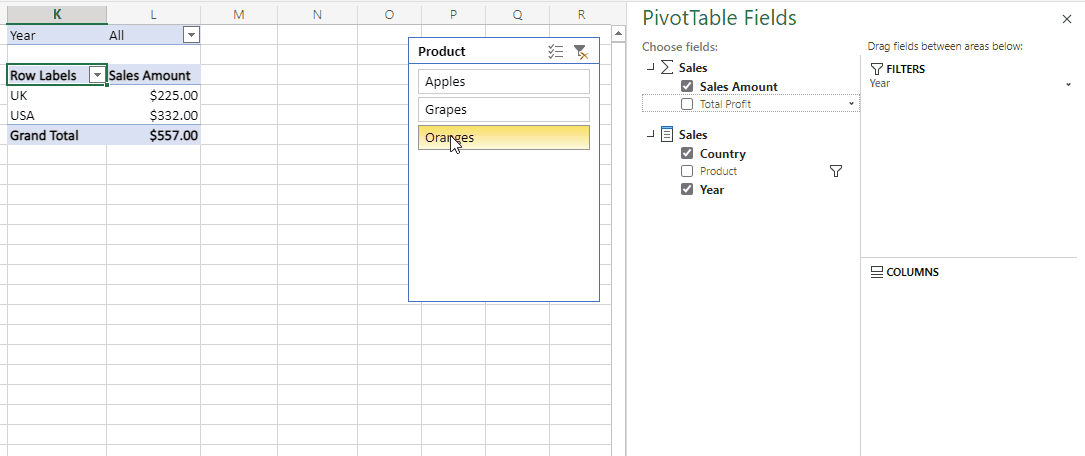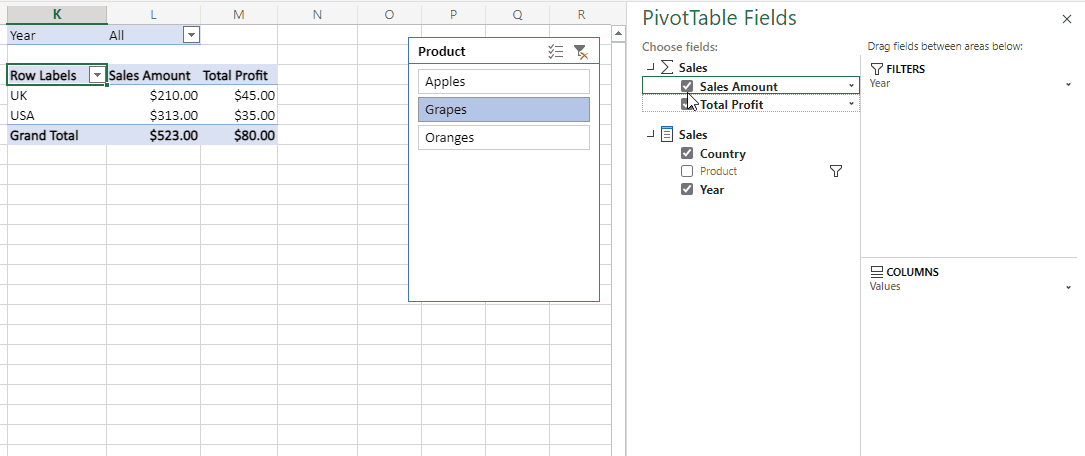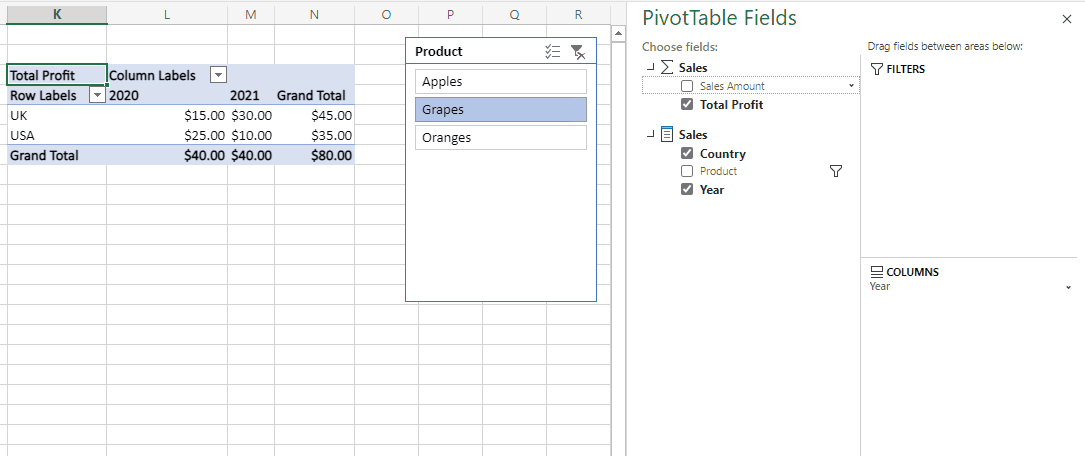
One of the factors that affects dataset refresh performance in Power BI is the number of objects that are refreshed in parallel. At the time of writing there is a default maximum of six objects that can be refreshed in parallel in Power BI Premium but this can be increased by using custom TMSL scripts to run your refresh.
A few months ago I blogged about how partitioning a table in Power BI Premium can speed up refresh performance. The dataset I created for that post contains a single table with nine partitions, each of which is connected to a CSV file stored in ADLSgen2 storage. Using the technique described by Phil Seamark here I was able to visualise the amount of parallelism when the dataset is refreshed in a Premium Per User workspace:

In this case I started the refresh from the Power BI portal so the default parallelism settings were used. The y axis on this graph shows there were six processing slots available, which means that six objects could be refreshed in parallel – and because there are nine partitions in the only table in the dataset, this in turn meant that some slots had to refresh two partitions. Overall the dataset took 33 seconds to refresh.
However, if you connect from SQL Server Management Studio to the dataset via the workspace’s XMLA Endpoint (it’s very similar to how you connect Profiler, something I blogged about here) you can construct a TMSL script to refresh these partitions with more parallelism. You can generate a TMSL script by right-clicking on your table in the Object Explorer pane and selecting Partitions:

…then, in the Partitions dialog, selecting all the partitions and clicking the Process button (in this case ‘process’ means the same thing as ‘refresh’):

…then, on the Process Partition(s) dialog, making sure all the partitions are selected, selecting Process Full from the Mode dropdown:

…and then clicking the Script button and selecting Script Action to New Query Window:

This generates a new TMSL script with a Refresh command that refreshes all the partitions:

This needs one more change to enable more parallelism though: it needs to be wrapped in a TMSL Sequence command that contains the maxParallelism property. Here’s the snippet that goes before the refresh (you also need to close the braces after the Refresh command too):
{
"sequence":
{
"maxParallelism": 9,

Executing this command refreshed all nine partitions in parallel in nine slots:

As you can see, increasing the number of refresh slots in this way can have a big impact on refresh performance – although, of course, you need to have enough tables or partitions to take advantage of any parallelism and you also need to be sure that your data source can handle increased parallelism. You can try setting MaxParallelism to any value up to 30 although no guarantees can be made about how many slots are available at any given time. It’s also worth pointing out that there are scenarios where you may want to set maxParallelism to a value that is lower than the default of six, for example to reduce to load on data sources that can’t handle many parallel queries.
[Thanks to Akshai Mirchandani for the information in this post]