A few weeks ago my colleague Dany Hoter wrote a post on the Azure Data Explorer blog about how using columns on fact tables as dimensions in DirectQuery mode can lead to errors in Power BI. You can read it here:
In the post he mentioned that he could reproduce the same behaviour in SQL Server, so I thought it would be good to show an example of this to raise awareness of the issue because I think it’s one that anyone using DirectQuery mode on any data source is likely to run into.
Consider a simple DirectQuery dataset built from the ContosoRetailDW SQL Server sample database:

There are two important things to point out here:
- The FactOnlineSales table has over 12 million rows
- The SalesOrderNumber column on the FactOnlineSales table is an example of a degenerate dimension, a dimension key in the fact table that does not have a related dimension table. This typically happens when it would make no sense to create a separate dimension table because it would be the same, or almost the same, granularity as the fact table.
Now if you try to build a simple table visual in a report connected to this dataset that has the SalesOrderNumber column and a measure that sums up the value of the SalesAmount column (ie with a definition of SUM(FactOnlineSales[SalesAmount] ) ) you’ll get the following error:
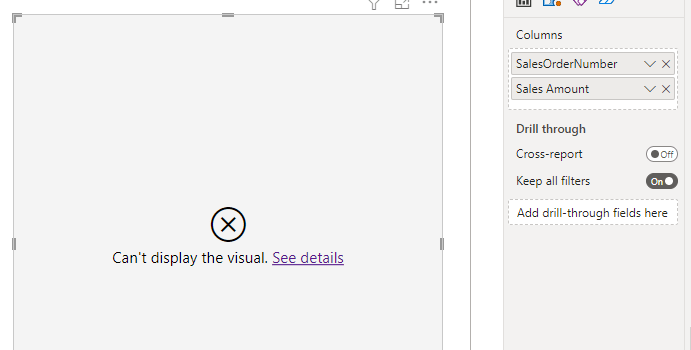

The resultset of a query to external data source has exceeded the maximum allowed size of ‘1000000’ rows.
This isn’t really surprising: you’ll get this error in DirectQuery mode any time Power BI generates a query against a data source that returns more than one million rows. You can increase this threshold using the Max Intermediate Row Set Count property on a Premium capacity but to be honest, if Power BI is trying to get this much data, you could still run into other performance or memory problems so the best thing to do is to redesign your report to avoid this problem. In this particular example you should question why you need a report with a table that has more than one million rows in it (I suspect the answer from the business will be “to export it to Excel”, which is another argument…).
In many cases you can avoid the error by applying a filter to the visual. In my example filtering the visual to display just the data for January 1st 2007, by applying the filter on the Datekey column of the DimDate table, means you don’t get an error because no SQL query will be generated that returns more than one million rows:

However, the bad news is that if you use slightly more complex DAX in your measure you are still likely run into the same error. For example, if you create a new measure with the following definition:
Error Demo = var s = [Sales Amount] return if(s>0, s)
[Yes, I know the measure definition doesn’t make much sense but it’s just a way of reproducing the problem]
….you’ll get the error even with the filter applied:

Why is this? Looking at the various SQL queries generated by Power BI for this visual it’s easy to find the cause of the error:
SELECT
TOP (1000001) [t1].[SalesOrderNumber]
FROM
(
(
select [$Table].[OnlineSalesKey] as [OnlineSalesKey],
[$Table].[DateKey] as [DateKey],
[$Table].[StoreKey] as [StoreKey],
[$Table].[ProductKey] as [ProductKey],
[$Table].[PromotionKey] as [PromotionKey],
[$Table].[CurrencyKey] as [CurrencyKey],
[$Table].[CustomerKey] as [CustomerKey],
[$Table].[SalesOrderNumber] as [SalesOrderNumber],
[$Table].[SalesOrderLineNumber] as [SalesOrderLineNumber],
[$Table].[SalesQuantity] as [SalesQuantity],
[$Table].[SalesAmount] as [SalesAmount],
[$Table].[ReturnQuantity] as [ReturnQuantity],
[$Table].[ReturnAmount] as [ReturnAmount],
[$Table].[DiscountQuantity] as [DiscountQuantity],
[$Table].[DiscountAmount] as [DiscountAmount],
[$Table].[TotalCost] as [TotalCost],
[$Table].[UnitCost] as [UnitCost],
[$Table].[UnitPrice] as [UnitPrice],
[$Table].[ETLLoadID] as [ETLLoadID],
[$Table].[LoadDate] as [LoadDate],
[$Table].[UpdateDate] as [UpdateDate]
from [dbo].[FactOnlineSales] as [$Table]
)
)
AS [t1]
GROUP BY [t1].[SalesOrderNumber]
Why is this query generated? Why is there no WHERE clause applying the date filter? When a DAX query is run Power BI does the following:
- Send dimension queries per unique dimension table. Only filters directly placed on the dimension table apply in this case.
- Send measure queries for each measure. All filters may apply in this case.
- Join the results from 1 and 2.
Sometimes, as in the example where just the SUM measure is used, it can optimise the dimension queries and apply the filter from the dimension table too. Sometimes, as in the last example above, it can’t and it runs a dimension query asking for all the distinct values from SalesOrderNumber in the fact table. You can try to work around it by rewriting your DAX, by filtering on the fact table and not the dimension table – applying a filter on the Datekey column of FactOnlineSales for 1/1/2007, rather than on the Datekey column of DimDate, results in no error – or using a dynamic M parameter to get more control over the queries generated. However the best course of action is to avoid using any column from a large fact table as a dimension, whether it’s a legitimate degenerate dimension or a column that should really be modelled in a separate dimension table.
[Thanks to Dany Hoter and Jeffrey Wang for the information in this post]
UPDATE February 2023: in some cases you may be able to avoid this error by building an aggregation table https://blog.crossjoin.co.uk/2023/02/08/avoiding-the-maximum-allowed-size-error-in-power-bi-directquery-mode-with-aggregations-on-degenerate-dimensions/
Muchas gracias Chris ahora entiendo un poco mas, porque tuve un caso similiar utilizando un DAX utilizando la funcion If( isblank(), , ) para colocar valor cero en blancos.
Thanks very much for writing about this. It helps explain why I have been getting these errors in a Power BI report that I have been building to analyze clinical encounter data at the hospital I work for. Unfortunately, however, there is no way to get around the offending degenerate dimension in my data set: patient medical record number (MRN). Pretty much any meaningful analysis of hospital and outpatient utilization will necessarily involve counting the distinct number of MRNs.
In a typical fact table of clinical encounters, the granularity of the MRN column is very similar to that of the primary key (encounter ID). We see more than a million unique patients per year, but any given individual has less than 3 encounters per year. Encounter-based data models can easily grow to multiple millions of rows if the use case involves analyzing trends in utilization over multiple years, making DirectQuery a much more viable storage mode option.
Do you have any suggestions for strategies to optimize visualizations and/or models where it’s simply not possible to get away from high-granularity degenerate dimensions?
I think your only option will be to see if can work around the problem with dynamic M parameters, but I’m not sure if it’s possible