Following on from my last two posts comparing the performance of importing data from ADLSgen2 into Power BI using the ADLSgen2 connector and going via Synapse Serverless (see here and here), in this post I’m going to look at a third option for connecting to CSV files stored in ADLSgen2: connecting via a Common Data Model folder. There are two ways to connect to a CDM folder in Power BI: you can attach it as a dataflow in the Power BI Service, or you can use the CDM Folder View option in the ADLSgen2 connector.
First of all, let’s look at connecting via a dataflow. Just to be clear, I’m not talking about creating a new entity in a dataflow and using the Power Query Editor to connect to the data. What I’m talking about is the option you see when you create a dataflow to attach a Common Data Model folder as described here:
This is something I blogged about back in 2019; if you have a folder of CSV files it’s pretty easy to add the model.json file that allows you to attach this folder as a dataflow. I created a new model.json file and added it to the same folder that contains the CSV files I’ve been using for my tests in this series of blog posts.

Here’s what the contents of my model.json file looked like:
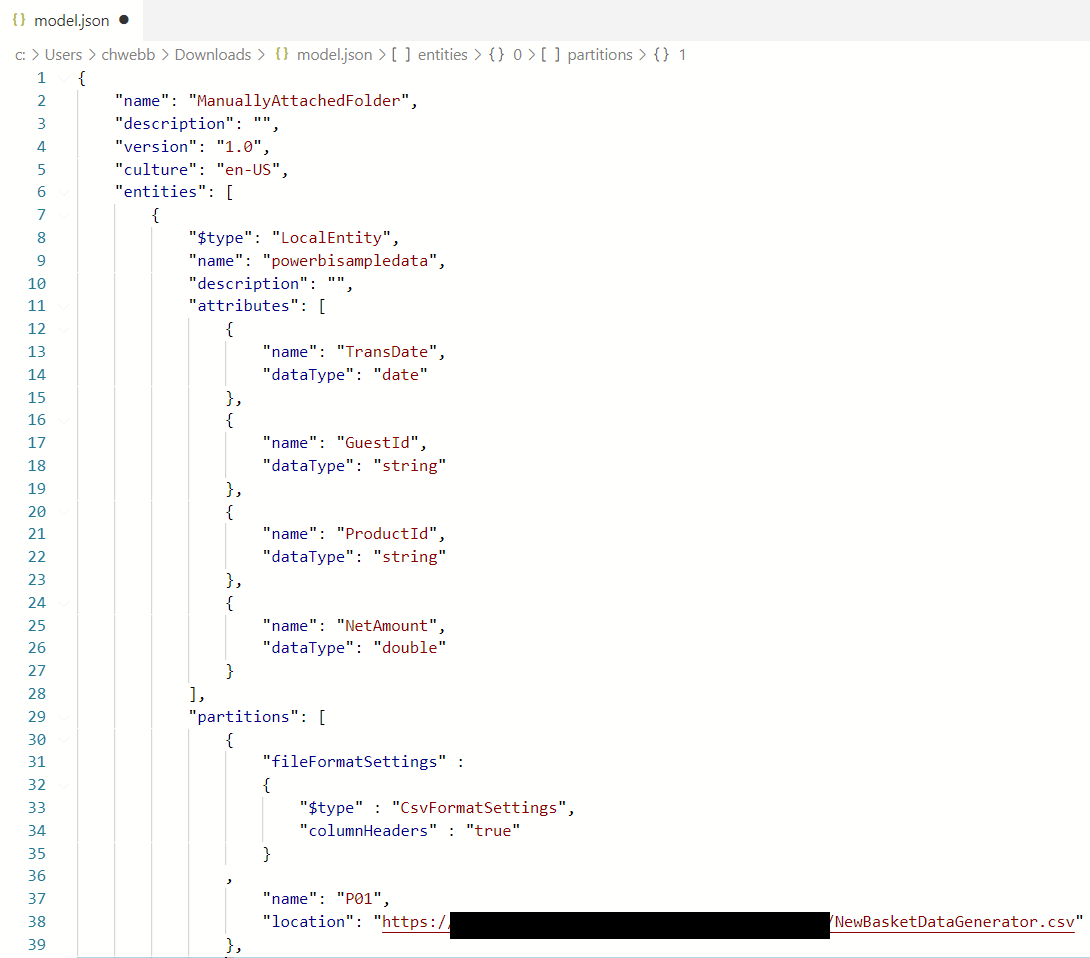
Something to notice here is that I created one CDM partition for each CSV file in the folder; only the first CDM partition is visible in the screenshot. Also, I wasn’t able to expose the names of the CSV source files as a column in the way I did for the ADLSgen2 connector and Synapse Serverless connector, which means I couldn’t compare some of the refresh timings from my previous two posts with the refresh timings here and had to rerun a few of my earlier tests.
How did it perform? I attached this CDM folder as a dataflow, connected a new dataset to it and ran some of the same tests I ran in my previous two blog posts. Importing all the data with no transformations (as I did in the first post in this series) into a single dataset took on average 70 seconds in my PPU workspace, slower than the ADLSgen2 connector which took 56 seconds to import the same data minus the filename column. Adding a step in the Power Query Editor in my dataset to group by the TransDate column and add a column with the count of days (as I did in the second post in this series) took on average 29 seconds to refresh in my PPU workspace which is again slightly slower than the ADLSgen2 connector.
Conclusion #1: Importing data from a dataflow connected to a CDM folder is slower than importing data using the ADLSgen2 connector with the default File System View option.
What about the Enhanced Compute Engine for dataflows? Won’t it help here? Not in the scenarios I’m testing, where the dataflow just exposes the data in the CSV files as-is and any Power Query transformations are being done in the dataset. Matthew Roche’s blog post here and the documentation explains when the Enhanced Compute Engine can help performance; if I created a computed entity to do the group by in my second test above then that would benefit from it for example. However in this series I want to keep a narrow focus on testing the performance of loading data from ADLSgen2 direct to Power BI without staging it anywhere.
The second way to import data from a CDM folder is to use the CDM Folder View option (which, at the time of writing is in beta) in the ADLSgen2 connector:
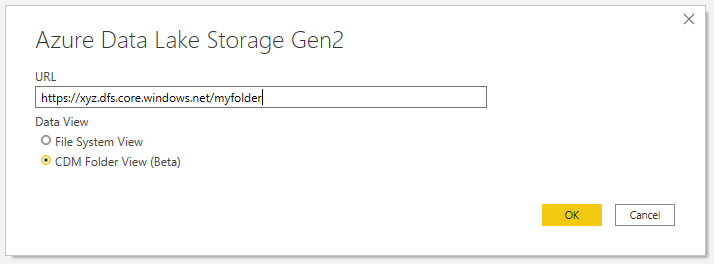
I expected the performance of this method to be the same as the dataflow method, but interestingly it performed better when loading all the data with no transformations: on average it took 60 seconds to refresh the dataset. This was still a bit slower than the 56 seconds the ADLSgen2 connector took using the default File System View option to return the same data minus the filename column. I then ran the test to create a group by on the Transdate column and that resulted in an average dataset refresh time of 27 seconds, which is exactly the same as the ADLSgen2 connector with the default File System View option.
Conclusion #2: Importing data from a Common Data Model folder via the ADLSgen2 connector’s CDM Folder View option may perform very slightly slower, or about the same as, the default File System View option.
So no performance surprises again, which is a good thing. Personally, I think exposing your data via a CDM folder is much more user-friendly than giving people access to a folder full of files – it’s a shame it isn’t done more often.
Hi Chris, thanks for pointing this out… I’d love to see more data lakes supporting CDM format but I’m wondering why we’re still stuck to CDM V1 (using model.json) with Power BI Dataflows and not leveraging CDM V2 (using the manifest files). ADF is already supporting it and it helps so much with i.e. partitioning by allowing wildcards etc. The ADLS Gen2 CDM interface already seems to support V2 but dataflows don’t…
I know, support for CDM V2 in dataflows is something we’re working on.
An important difference is the time required to enumerate files: https://www.sqlbi.com/blog/marco/2020/05/29/optimizing-access-to-azure-data-lake-storage-adls-gen-2-in-power-query/
Yes, I saw that post. I’m using a container with no other files in for my testing.
Good to know. The impact is huge when you have many “small” files (2-3 MB each).