After my post on tuning Excel cube functions last week there was some (justified) moaning on Twitter about their performance. This got me thinking about other things you could do with cube functions that might improve performance and I had a crazy idea…
Late last year two new DAX functions were introduced which didn’t get much attention: ToCSV and ToJSON. They allow you to evaluate a table expression and return the result as text in either CSV or JSON format, for example from a measure. They are intended to make debugging easier. What I realised is that you can use ToCSV to return a table of data in CSV format in a single Excel cube formula in a cell in your worksheet and then use dynamic arrays to turn that back into a table in Excel.
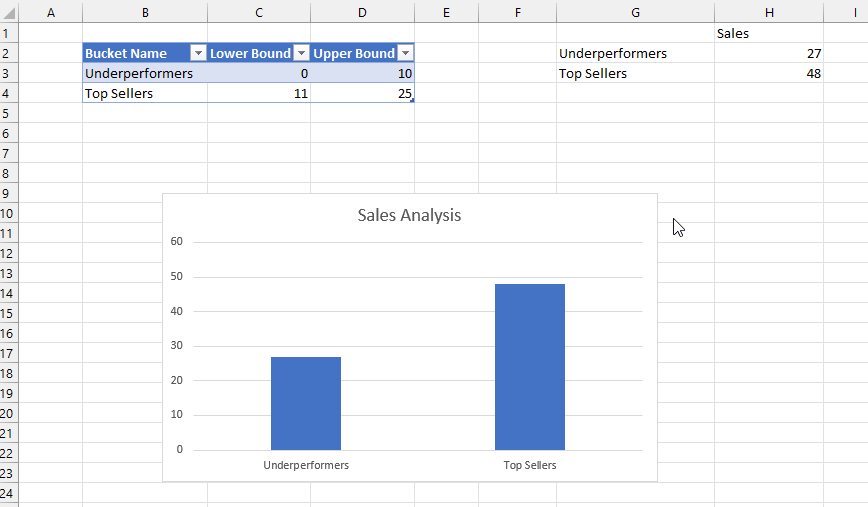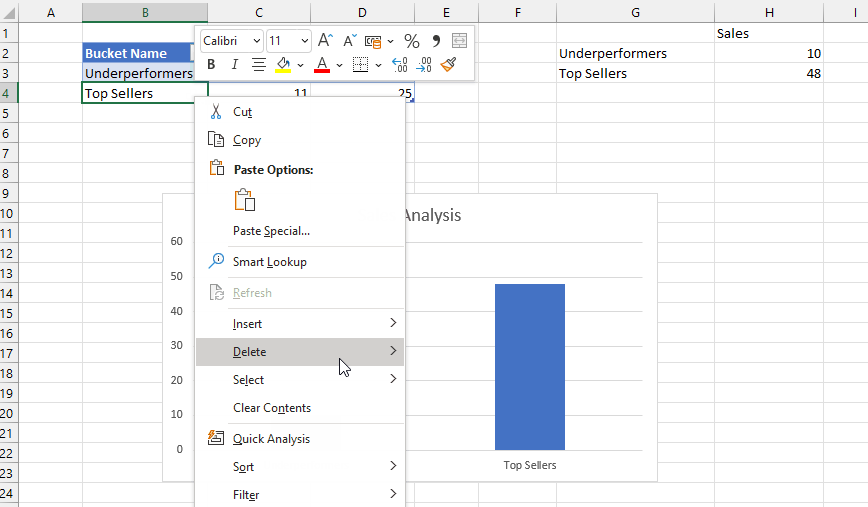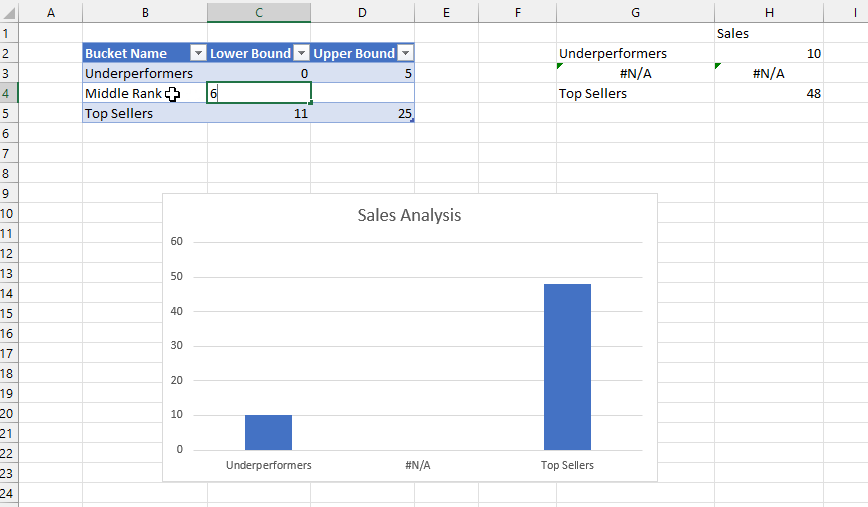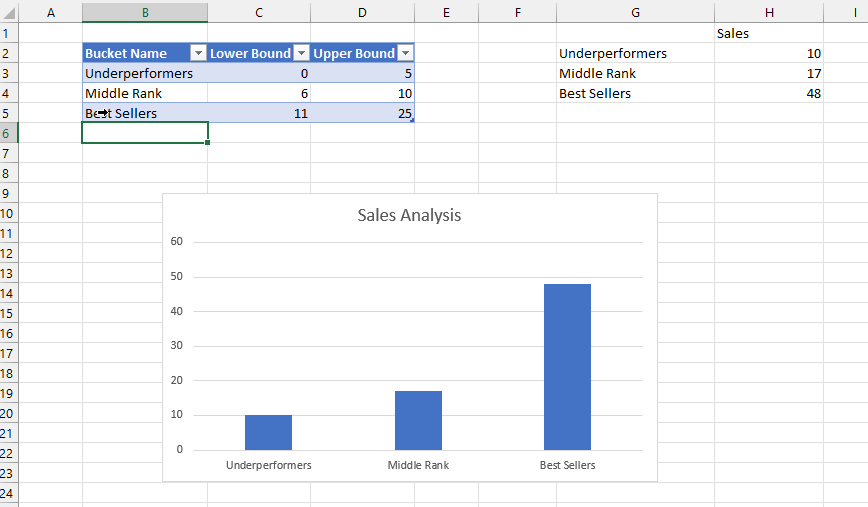
Using the dataset from last week’s post, with the following tables:

…I created the following measure:
MyTable =
TOCSV (
SUMMARIZE (
'Country',
Country[Country],
"Sales Amount", [Sales Amount],
"Target Amount", [Target Amount]
)
)You can see it return a text value in CSV format from the following Power BI report:

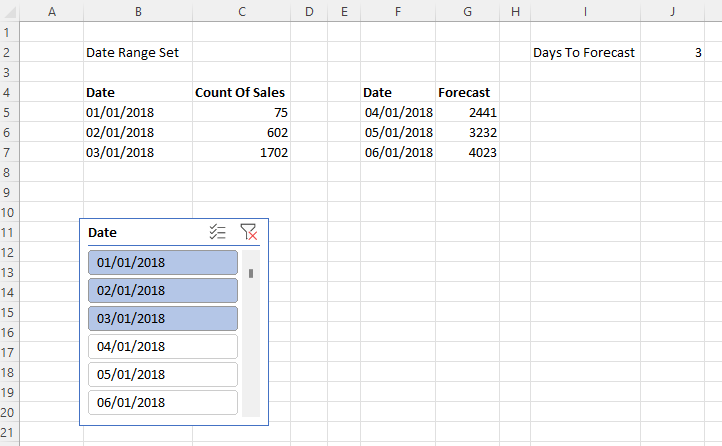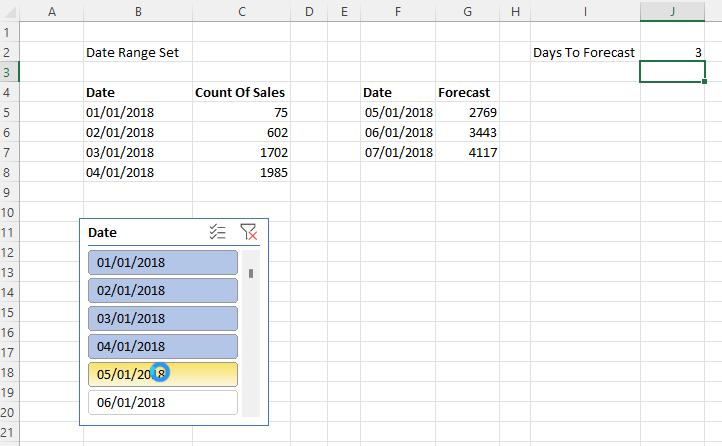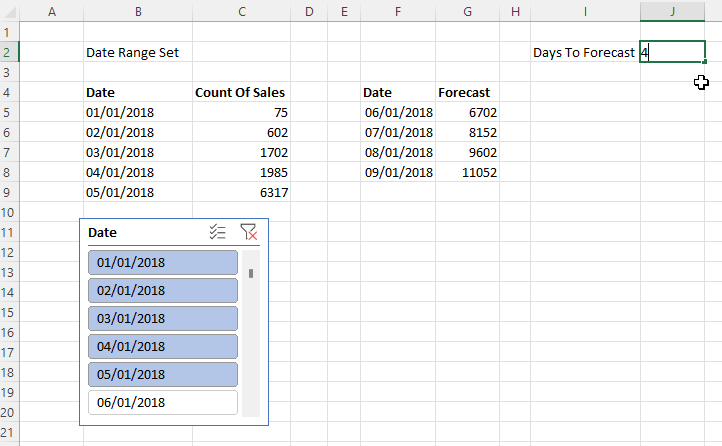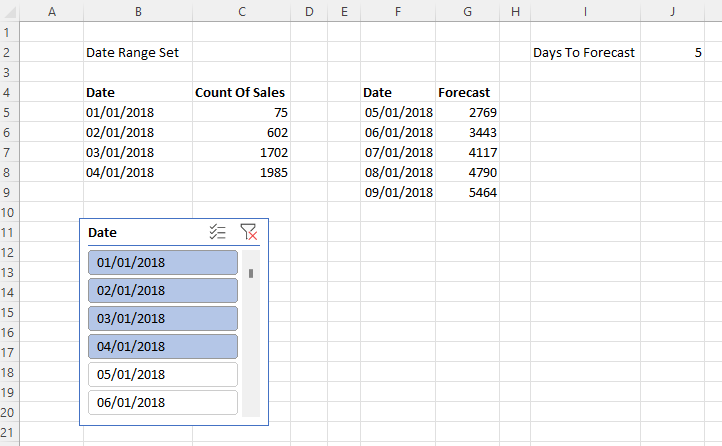
I then created a connection to the published dataset from Excel and using a single formula in cell B3 and two slicers connected to the Product and Continent fields was able to create the following report:
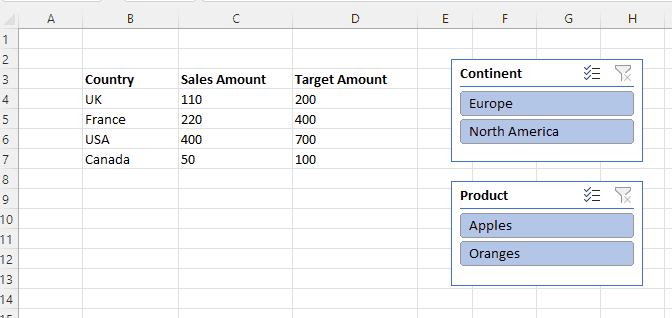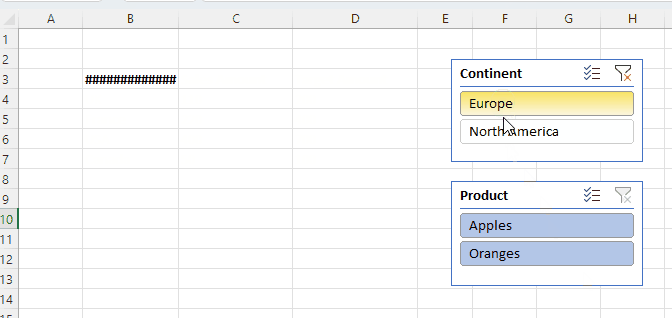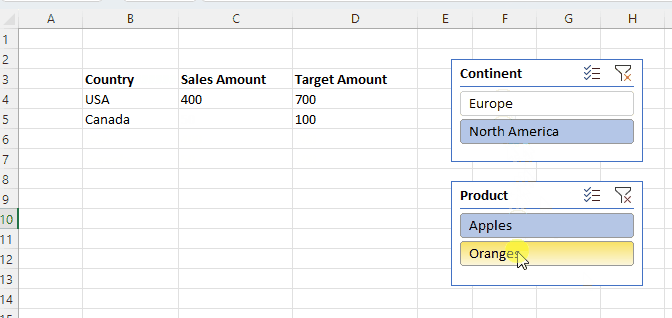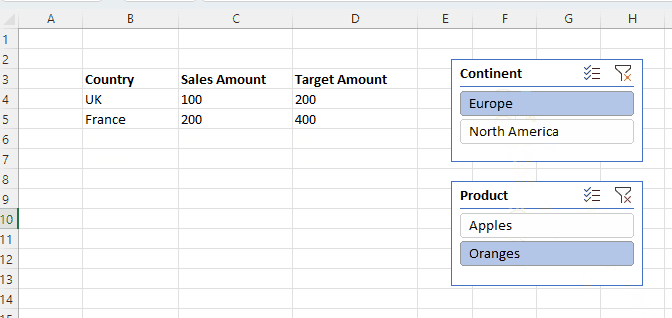
Here’s the formula in B3:
=
LET(
CSV,
CUBEVALUE("CubeFunctionsOptimisationDataset",
CUBEMEMBER("CubeFunctionsOptimisationDataset","[Measures].[MyTable]"),
Slicer_Product,Slicer_Continent),
SplitToCells,
TEXTSPLIT(CSV,",", CHAR(10)),
HeaderRow,
TAKE(SplitToCells,1),
DataRows,
DROP(SplitToCells,1),
RemoveSquareBracketsFromHeaders,
TEXTBEFORE(TEXTAFTER(HeaderRow, "["),"]"),
Recombine,
VSTACK(RemoveSquareBracketsFromHeaders, DataRows),
Recombine)Note: you also need to click the Wrap Text option on the ribbon for this cell for this to work properly.
There’s a lot going on here but the Excel Let function makes it easy to break the formula up and understand it. Here’s what each step in the formula does:
- CSV uses the CubeMember and CubeValue functions to get the result of the MyTable measure for the current selection in both slicers.
- SplitToCells takes the single text value returned by the previous step and uses the TextSplit function to turn it back into an array
- HeaderRow finds the first row in this array, which contains the column headers using the Take function
- DataRows finds all other rows, which contain the data in the table using the Drop function
- RemoveSquareBracketsFromHeaders takes the contents of HeaderRow and uses the TextBefore and TextAfter functions to find the names of each column and measure, which the ToCSV function returns between square brackets (for example it takes ‘Country'[Country] and returns Country, and takes [Sales Amount] and returns Sales Amount)
- Recombine then takes the new header row with the cleaned names and appends the array from DataRows underneath it, using the VStack function
This formula is a great candidate for use with the Lambda function so it can be easily reused.
There are a number of reasons this technique is interesting, even if it’s slightly hacky. First of all since the table is returned from a DAX expression that you write, and it’s returned by a single query, it could result in faster performance. Second, instead of just one cell returning one table, you can combine it with CubeMember functions to return multiple tables. In this example C3 and G3 contain CubeMember functions that the tables immediately below them refer to:

I haven’t tested this with very large tables. Since there is a limit on the amount of text that a measure can return then there is a limit on the size of the array that can be displayed; I’m also not sure what the performance overhead of the Excel formula to convert the text to the array is.